
Intelligence is not only linguistic, but also visual and physical. As LLMs are becoming increasingly more mature technology and are successfully used in multiple digital domains spanning emails editing, text summarisation or even coding, they lack visual and physical understanding of the world. On one hand, they can recite complex physics phenomena using formal languages; on the other hand, they don’t fully grasp object permanence, motion understanding, or how objects collide.
Today, we release PhysicalRealismBench-U — the physical realism benchmark with a synthetic dataset containing programmatic physics violations — along with an evaluation pipeline to evaluate state-of-the-art VLMs in the context of physics understanding.
We show that even the best existing models fail at fundamental physical reasoning tasks, which even kids would easily resolve. Our findings are especially critical in the fast-emerging space of Physical General Intelligence or World Models.
The Problem: Intuitive Physics
A cat trying to gracefully catch a bird, or a basketball player who skilfully shoots into the basket do not need to write equations of motions to perform their tasks. Instead, they intuitively understand laws of physics. They “know” how objects interact with each others, or how they fall. This happens due to the combination of evolution and lifelong learning.
The same principles hold in the physical general intelligence. An autonomous driving system that doesnʼt respect object permanence across occlusions will make catastrophic planning errors. A robot that fails to conserve support relations will take dangerous actions. Yet existing evaluation approaches fall short of catching those failures as they often focus on linguistic skills or generic understanding of concepts
in the image or videos.
Those shortcomings are becoming increasingly more important as often VLMs are re-purposed to serve as the “robotics brain” or used as a evaluator in various world model benchmarks such as VBench- 2. 0 , WorldModelBench, or PAIBench [citations], or as a reward function [citation to vlms are reward models as disguise].
Here, we show that current VLMs skip frames, rely on spatial heuristics (see Insight 2 Border Proximity Triggers False Reasoning), and miss fundamental violations. Those findings have important ramifications, e.g., if used to evaluate world models they can produce false sense of progress.
The question is not whether current models sometimes get physics wrong — they do. The question is how systematically they fail, and whether the field has the tools to measure and diagnose these failures precisely enough to drive improvement. Our findings suggest the answer is negative: even state-of-the-art VLMs fail to detect basic violations like objects vanishing or moving without cause, and existing benchmarks lack the attribution machinery needed to turn these failures into actionable insights. This motivates both PhysicalRealismBench-U and a broader call for the community to prioritise physical realism as a first-class evaluation citizen.

Where Existing Benchmarks Fall Short
Several recent benchmarks target physical reasoning, and our work is complementary — not competitive — to each. Our long-term goal is to enable scalable evaluation of physical realism in generated videos: does a video generator produce output that is not only visually plausible, but physically coherent? However, automatic generation evaluation increasingly relies on VLMs as judges. Before we can rely on those judges, we first need to understand whether they can reliably detect, localize, and explain physical violations themselves. We therefore describe both related strands below — understanding benchmarks, which test VLM physical reasoning, and generation benchmarks, which test physically coherent video generation — to clarify the design space and motivate why stronger understanding evaluation is a prerequisite for reliable generation evaluation.
Physion-Eval [UNDERSTANDING + GENERATION]
Concurrent work (Zhang et al., March 2026), closest in spirit. Physion-Eval covers both understanding and generation, and its headline finding — that the vast majority of generated videos contain a human-identifiable physical glitch while the best MLLM critic detects only a fraction — independently validates our thesis that VLMs cannot yet be trusted as physics judges.
PhysicalRealismBench is complementary along three axes. First, Physion-Eval's quantitative VLM evaluation compares real and generated videos that share only a first frame and asks for a binary "is this physically realistic?" judgment — a setup that conflates "is this generated?" with "does it have a glitch?", since real and generated videos differ in much more than physics. We instead pair each violation with a same-scene counterpart where only the violation differs. Second, Physion-Eval also has a rich expert-annotated dataset (timestamps, failure categories, natural-language reasoning), but VLMs are evaluated against it only qualitatively, on hand-picked examples, with free-form object references that are ambiguous when a scene contains multiple instances of the same class. We score attribution quantitatively across the full benchmark, with structured object IDs. Third, Physion-Eval reports more than one glitch per video on average, confounding attribution; our videos contain at most one violation.
For generation, Physion-Eval reports per-generator failure rates and severity from expert annotators, and reuses the perception study's real-vs-generated judgment gap as a coarse realism proxy.
PhysBench [UNDERSTANDING]
PhysBench is another closely-related benchmark on the understanding axis: it evaluates VLM physical understanding across four domains (object properties, object relationships, scene understanding, physics-based dynamics) and 19 subclasses (mass, elasticity, collisions, etc.) over 10,000 test entries, revealing that even GPT-4o fails systematically on physical reasoning.
PhysicalRealismBench differs in two key respects. First, we use synthetic data with programmatic violations, providing exact ground truth rather than human-annotated questions — this means evaluator accuracy can be measured precisely. Second, our attribution schema is organized by physical law rather than by physics topic. PhysBench's domains and subclasses are physics-relevant, but they carve up physics by aspect — not by underlying law. A failure on PhysBench's physics-based dynamics domain therefore cannot isolate whether the issue is with gravity, momentum conservation, or impenetrability.
PhysicalRealismBench instead binds every question to a specific physical law, object set, time span, and observable evidence, enabling per-law diagnostics that PhysBench's topic-level reporting cannot provide.
PAI-Bench [UNDERSTANDING + GENERATION]
PAI-Bench spans both axes, with tracks for generation, conditional generation, and understanding. On the understanding track — where our benchmarks overlap — PAI-Bench uses pre-defined multiple-choice questions assessed by a VLM. However, these questions mix physics-relevant reasoning with non-physics aspects: spatial-relationship checks ("is the mug above the brick?"), attributeverification ("is the mug yellow?"), temporal ordering ("does the mug move before hitting the brick?"), and action recognition sit alongside genuinely physical questions in the same evaluation. This dilutes the physics signal and makes it difficult to isolate where a model's physical understanding specifically fails versus where it struggles with spatial perception or attribute matching.
PhysicalRealismBench focuses every question on a specific physical law, providing the law-level, object-level, and temporal attribution needed for systematic diagnosis of physics reasoning capabilities.
WorldModelBench [GENERATION]
WorldModelBench targets the generation axis, introducing explicit physics-adherence checks for generated videos and arguing that subtle violations are invisible to traditional quality metrics. Its violation types remain global — the benchmark identifies that a video violates physics but doesn't attribute the failure to a specific object, time span, or law instance. WorldModelBench's own results (Table 5) further illustrate the challenge: their proposed fine-tuned judge (VILA-2B +CoT) achieves a 29.7% physics error rate — worse than both Gemini-1.5-Pro +CoT (28.3%) and the zero-shot VILA baseline (24.0%). Fine-tuning on physics data did not improve physics judgment, and even the best-performing judge disagrees with human ground truth nearly a quarter of the time. This again shows the need for a rigorous, systematic study of how VLMs assess physical realism — understanding their failure modes, biases, and perception limits before trusting them as judges. This is precisely the gap PhysicalRealismBench addresses.
VideoPhy-2 [GENERATION]
VideoPhy-2 evaluates generation through action-centric physical commonsense, covering 197 real-world actions with explicit per-law violation annotations. It reveals that conservation laws are the most frequently violated class. On the evaluation methodology side, it relies on human annotators for physics judgments. Our benchmark complements this by providing a fully automated pipeline with synthetic ground truth, and by adding the object-level attribution, temporal localization, and evidence grounding that VideoPhy-2 does not include.
Comparison Table (Understanding Benchmarks)
Each cell reflects what the benchmark's automated VLM evaluation provides; dataset annotations that aren't used in a quantitative metric are not counted.

PhysicalRealismBench: Physics-First, Scene-Specific, Attributable
PhysicalRealismBench is organized around two core design principles. The overarching goal is to turn implicit physics into measurable and diagnosable signals. This release focuses on physical understanding (Track U).
Design Principles
1. Physics-first, but not physics-only. Every benchmark item is anchored to a specific physical law, so each evaluation result is traceable to a named principle rather than to an aggregate quality score. But no judgment reduces to a closed-form physics check: every law we evaluate requires combining motion analysis with scene context. A gravity violation depends on both motion (is the object falling?) and context (what is or isn't supporting it). A pass-through depends on both object trajectories and the geometry of the surfaces they should not cross.
2. Scene-specific evaluation mapped to first principles. Each item carries structured ground truth: the physical law being tested, the relevant object(s), the relevant frame range, and the concrete failure mode when a violation is present. Questions are instantiated from per-law templates bound to concrete scenes — not abstract physics categories.
Track U: Physical Understanding
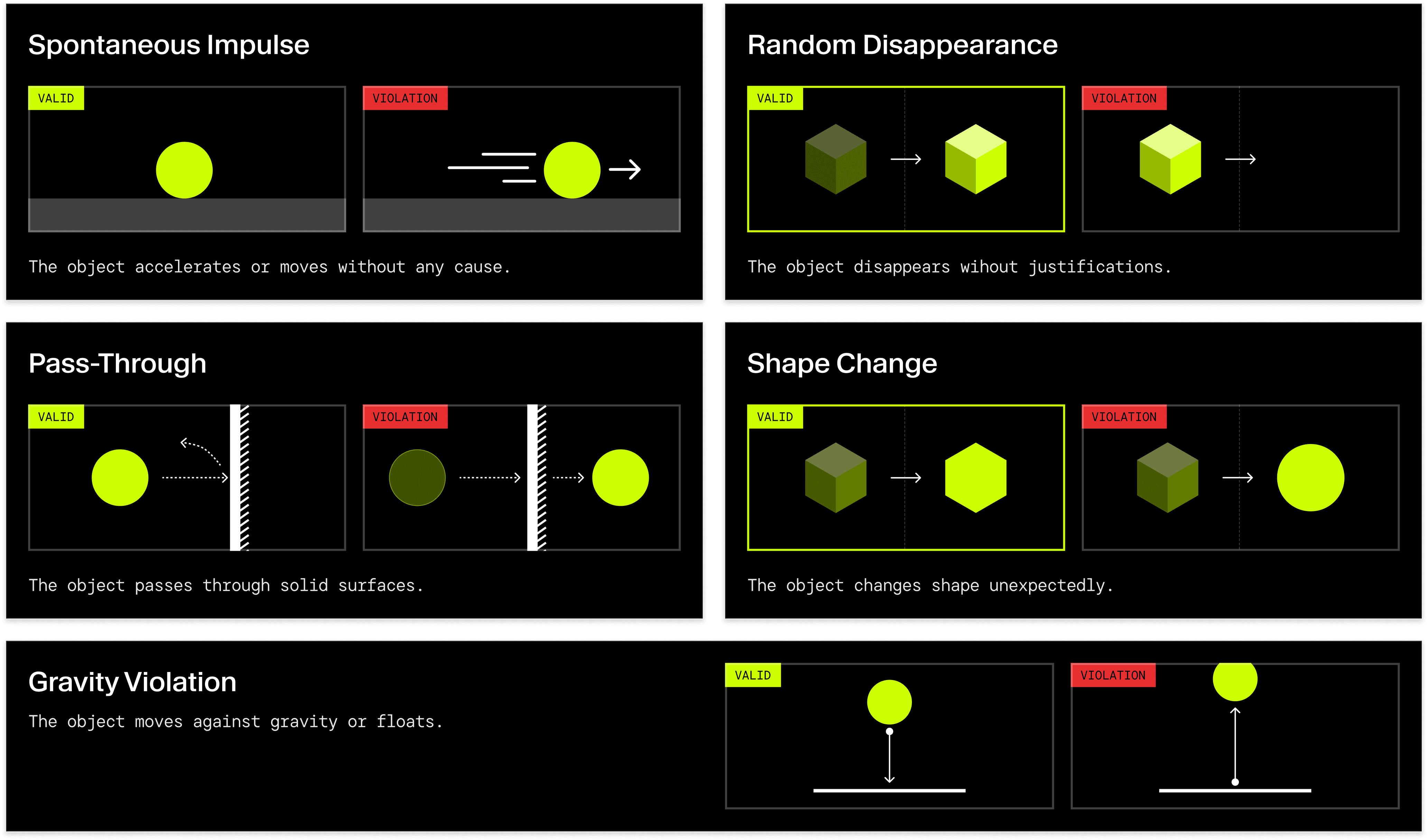
The released track evaluates whether VLMs can perceive and reason about physical events in videos. Given a video and a physics-grounded question, the model must decide for each target physical law whether it is obeyed or violated, and provide a short rationale explaining its judgment. The current release covers five violation categories grounded in fundamental physics (which we found to be most dominant in current T2V generations): spontaneous impulse (motion without cause, violating Newton's first law), random disappearance (objects vanishing, violating conservation/permanence), pass-through (objects interpenetrating, violating impenetrability), shape change (objects deforming unexpectedly, violating mass conservation), and gravity violations (objects hovering or falling inconsistently, violating gravity/support).
Physics Ontology
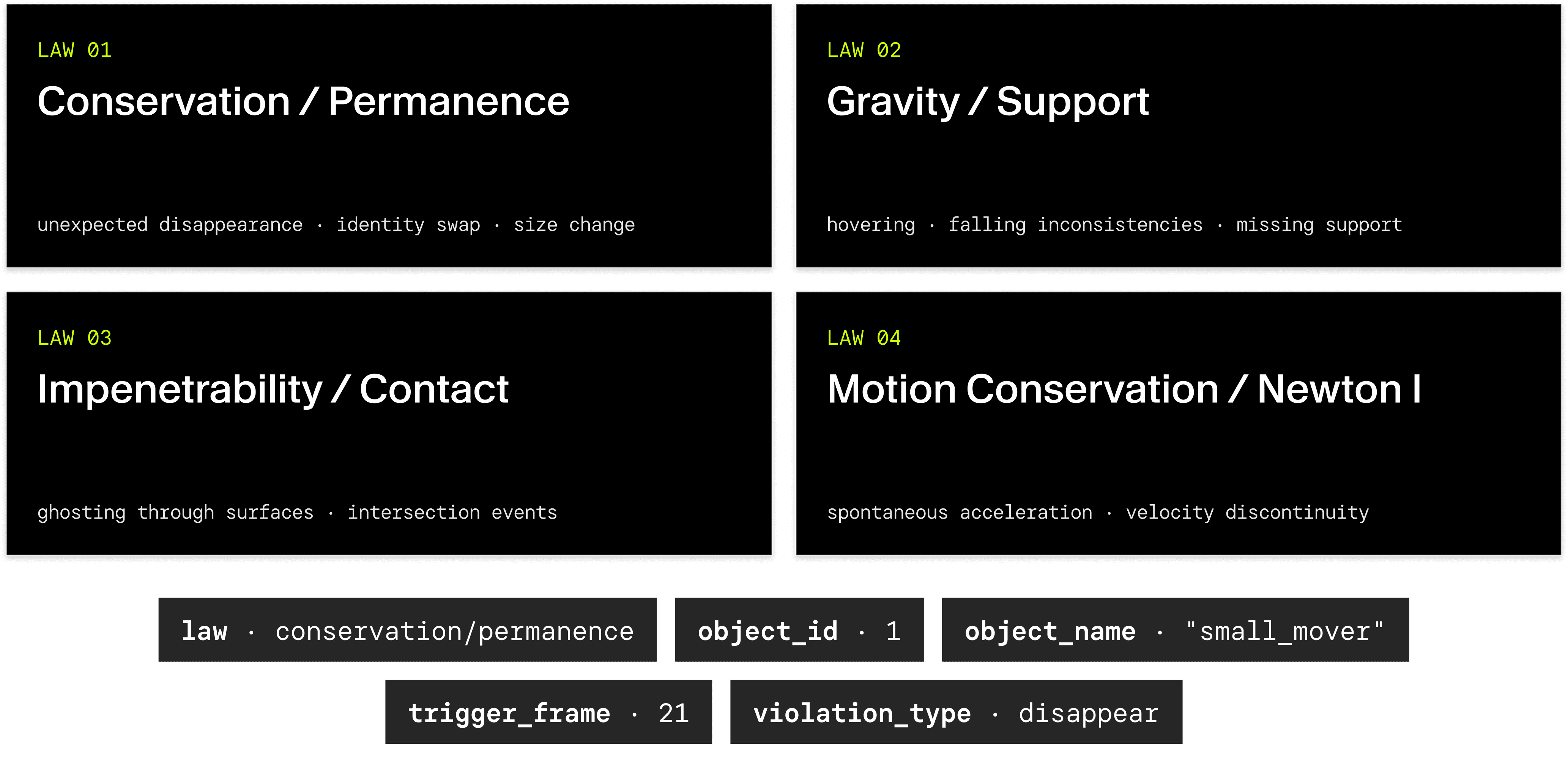
PhysicalRealismBench is designed around a physics ontology that maps every evaluation question to a specific physical law. The core law set defines four categories: conservation/object permanence (unexpected disappearance, identity swaps, size changes), gravity/support (hovering, falling inconsistencies, missing support), impenetrability/contact (ghosting through surfaces, intersection events), and motion conservation (spontaneous acceleration, velocity discontinuities):
(law, {object_id, object_name}, trigger_frame, violation_type)
For example, a ground truth entry might read: (conservation/permanence, {id: 1, "small_mover"}, frame 21, disappear) . This level of granularity lets us aggregate failure rates by law, by object, by violation type — and trace every score back to a specific object and moment in the video.
What We Release
This is not just a research report — it is a benchmark release and a call to action. Our evaluation shows that current VLMs lack the physical reasoning capabilities assumed by downstream applications. PhysicalRealismBench comprises four components:
Synthetic Benchmark Dataset — Videos with programmatic physics violations (and matched valid videos) covering five violation categories. Every video has known ground truth labels, enabling precise measurement of any evaluator's accuracy.
Baseline Results — We evaluate state-of-the-art VLMs, including Gemini 3.1 Pro and GPT-5.5. Across models, performance remains far from reliable physical understanding: F1 scores range from X to Y, showing that even leading VLMs struggle to detect and ground basic physics violations.
Findings — We present analyses that probe why VLMs fail on physical reasoning. The results suggest that models may not attend to every frame and often rely on spatial heuristics — such as border proximity — instead of reasoning from temporal evidence.
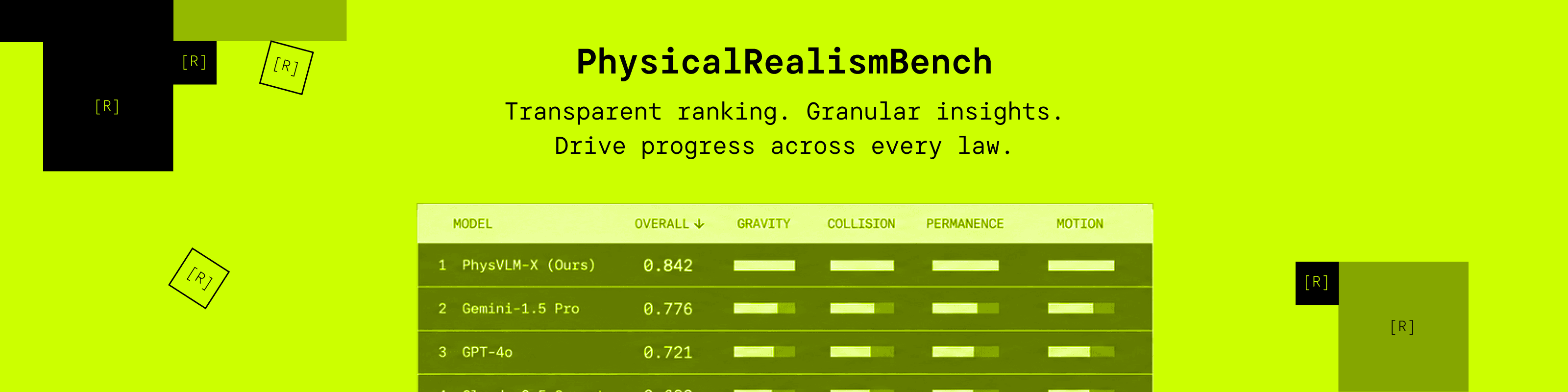
Leaderboard & Evaluation Page — A public leaderboard where results from any VLM can be submitted and compared, with overall scores and per-law breakdowns that show where each model succeeds or fails.
PhysicalRealismBench is designed for community use. If you are building or evaluating a VLM, you can run it against our dataset and directly compare to our baselines. Because the ground truth is synthetic and exact, there is no annotation ambiguity — a violation either exists or it doesn't. This makes PhysicalRealismBench a precise diagnostic tool, not a subjective quality judgment.
The PhysicalRealismBench Dataset
PhysicalRealismBench is built on a synthetic dataset generated using Nvidia Isaac Sim. We use assets provided by Nvidia and source additional assets from Polyhaven, Adobe Substance, and Fab. Every video is physically correct by construction — objects obey Newtonian mechanics, gravity, collision response, and material properties exactly as simulated. Violations are then injected programmatically: a single, controlled deviation from the physics (an object vanishing, passing through another, moving without cause, deforming, or hovering). This means the ground truth is exact and unambiguous — there is no annotation noise, no subjective judgment about whether a violation occurred.
The dataset contains 500 videos across five violation categories, organized as 250 matched pairs: each pair shows the same scene rendered twice — once with a single physical violation injected, once without. This pairing isolates the violation from scene content and rendering style, providing a clean controlled comparison.
We additionally include 50 occlusion-and-reappearance videos in which an object passes behind an occluder and then reappears normally. These are valid scenes (no violation), and we deliberately do not construct violation counterparts for them.

Dataset Structure: What the VLM Sees
Each sample to be evaluated consists of four components:
Video. — The simulated scene rendered with realistic textures and lighting.
Object ID overlays. — Each relevant object is assigned an integer ID and labeled with a bounding box on one frame. The VLM is asked to refer to objects by ID in its response, which makes the output programmatically matchable to ground truth — even when the scene contains multiple instances of the same class (e.g., two red balls).
Frame-counter overlay. — Some VLMs may not have direct awareness of time or frame numbers. We overlay a frame counter at the top-left of each video so the VLM can cite exact frame numbers when reporting where a violation occurs.
Per-law question prompt. — For each video, the VLM is asked one yes/no question per physical law in the core set (does this video violate <law> ?). The response is parsed for the binary answer, the ID(s) of any violating object(s), and the frame range — all three feed the automated scoring pipeline.
Ground truth. Every sample carries a structured ground-truth tuple (law, {object_id, object_name}, trigger_frame_range, violation_type) , which is matched component-wise against the VLM's parsed response. Because both ground truth and predicted reference use the same object IDs, the match is exact rather than text-fuzzy.
Design Principles for Synthetic Data
Early experiments showed that the visual design of synthetic scenes is critical for VLM evaluation — not because the physics changes, but because VLMs rely heavily on visual cues to interpret the scene. Through iterative testing, we identified several requirements that guided the final dataset design:
1. Realistic textures on all surfaces. Untextured objects and ground planes cause VLMs to misinterpret the scene geometry — for instance, claiming an object is "floating in air" when it is resting on a featureless grey surface. All objects and ground planes use realistic materials.
2. Visual cues for depth and spatial context. Both the background and the ground plane must provide texture and features that convey depth and position. Homogeneous or untextured surfaces strip away the spatial context that VLMs need to judge whether an object has moved, fallen, or changed position.
3. Controlled object velocities. Objects must move slowly enough to be visible across multiple frames. We found that very fast motions — where an object appears in only one or two frames before a violation — are systematically missed by VLMs. This is consistent with our finding that VLMs do not examine every frame (see Insight 1), and further confirms the need for careful velocity control in synthetic evaluation data.

Baseline Results: Why Physical Realism Needs More Attention
To establish baselines and demonstrate PhysicalRealismBench's utility, we evaluated state-of-the-art VLMs on the full dataset. These results serve as reference points for anyone evaluating their own models — but more importantly, they reveal how far current models are from reliable physical reasoning. Even on synthetic scenes with unambiguous violations, the best models struggle: e.g., our headline F1 reaches only 39.5% with Gemini 3.1 Pro. If VLMs cannot reliably detect an object vanishing in a controlled environment, they cannot be trusted as physics judges for real-world video, nor can the video generation models they are meant to evaluate.

Insight 1: VLMs Don't Examine Every Frame
We overlaid random numbers on each frame and asked the VLM to report them. It recognized between 80-100% of the overlaid numbers. When the same frames were sent as individual images in a single API call (rather than as a video), recognition was 100%, showing the problem is not the model struggling with the OCR task. When we used consecutive (predictable) numbers instead of random ones, video-mode accuracy also hit 100% — strongly suggesting the model interpolates or "cheats" rather than inspecting each frame.

Implication: VLMs processing video inputs appear to skip or interpolate frames, relying on temporal coherence priors rather than exhaustive frame inspection. This means single-frame events — a one-frame position change, a brief appearance — may go undetected. For physical evaluation, this is a fundamental reliability constraint.
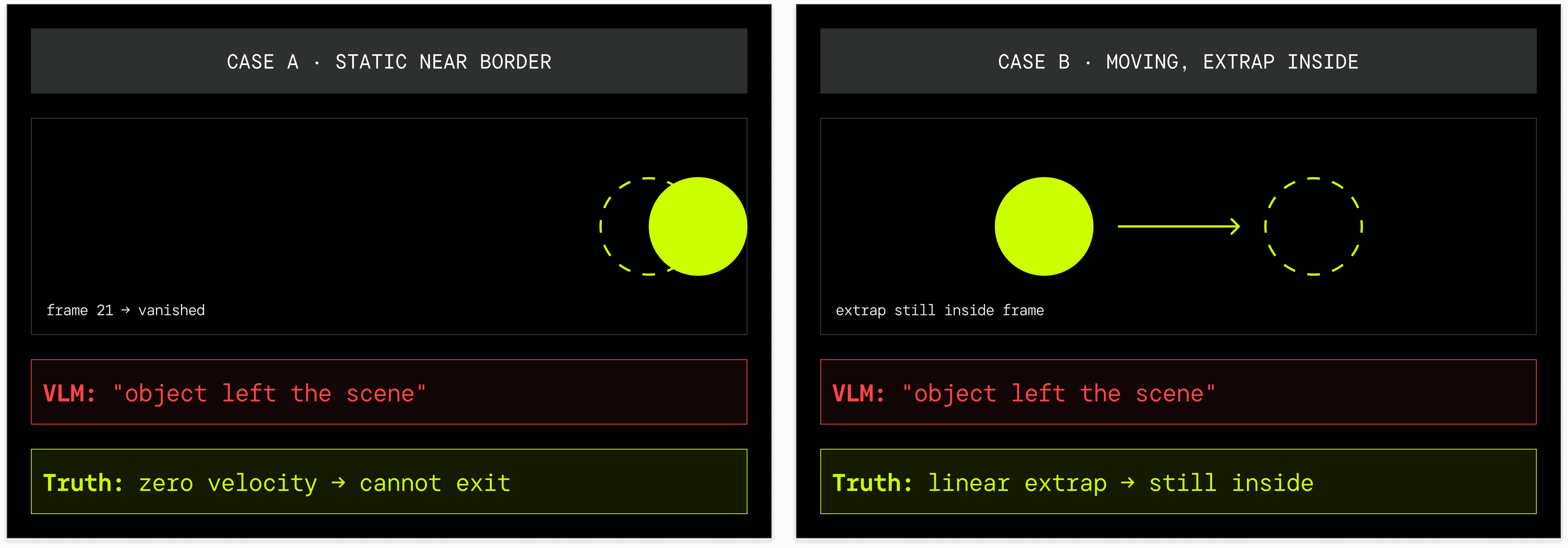
Insight 2: Border Proximity Triggers False Reasoning
When an object near the image border disappears, we often saw VLMs tend to claim the object "left the scene", even though the object trajectory shows no outward motion, or its linear extrapolation places the object still inside the frame at the moment it vanishes.
This indicates VLM struggle combining position, velocity, and frame timing to verify whether an exit is geometrically plausible, revealing a lack of basic spatiotemporal motion and extrapolation understanding.
Insight 3: Position Augmentation Substantially Helps
Providing per-frame object positions as tuples (x, y, t) in the prompt — derived from segmentation masks — substantially improves classification performance across multiple violation types (disappearance, random impulse, initial motion). That such a large gain comes from coordinates fed as text suggests VLMs' vision-based physical reasoning is markedly weaker than their text-based reasoning: the underlying physics knowledge is present in the language model but does not transfer cleanly into the vision-understanding component.

Insight 4: Motion Detection Has an Asymmetric Temporal Bias
In a controlled sweep varying the number of frames an object spends at position A, position B, and then disappears, we found the VLM fails to detect motion specifically when the object lingers at position A for many frames but appears at B for only a few. The reverse (short A, long B) is detected correctly. Out of 108 tested configurations, 12 produced failures — all with this asymmetric pattern. This suggests a recency or salience bias in temporal attention.
The case for a stronger focus on realism: Taken together, these findings paint a clear picture: current VLMs do not reliably reason about physics in video. They skip frames, rely on spatial heuristics instead of temporal analysis, and miss events that any human would catch immediately. These are not edge cases — they are failures on basic Newtonian mechanics in clean, synthetic scenes with unambiguous violations.
If VLMs struggle on controlled synthetic data, their reliability on noisy real-world video is fundamentally in question. This has direct consequences: VLMs are increasingly used as judges for video generation quality, and video generators are increasingly deployed as world models for robotics and autonomous systems. A weak physics evaluator produces a false sense of progress — models appear to improve while their physical understanding stagnates. We believe the field needs to treat physical realism as a first-class evaluation axis, with dedicated benchmarks, explicit diagnostics, and public accountability through leaderboards. That is what PhysicalRealismBench aims to provide.
How PhysicalRealismBench Scores: Classification + Reasoning Attribution
PhysicalRealismBench evaluates VLMs on two levels. Throughout, we treat positive = violation, negative = no violation for each (video, law) pair.
Level 1: Classification F1 — can the model detect violations?
For each (video, law) pair, the VLM produces a yes/no judgment. Comparing this to ground truth gives a TP/FP/FN/TN per (video, law), and we report standard classification metrics over all pairs (precision, recall, F1 as the headline). F1 also compensates for the strong class imbalance in the data — each video has at most one violation across five laws, so positives are rare — which makes accuracy uninformative.
Level 2: Joint F1 — the leaderboard metric
Classification alone doesn't tell us whether the model actually understood the physics. We therefore use a stricter F1 in which a (video, law) pair is counted as a TP only if the model both (a) correctly classifies the law as violated and (b) provides correct reasoning. Reasoning is correct iff the response references both the violating object (by ID) and the violation's frame range. The resulting metric is realism F1 score.
This is the single number reported on the leaderboard (39.5% for Gemini 3.1 Pro). It penalizes a model for both detection failures and ungrounded reasoning, which prevents the "lucky classifier" problem — a model that detects something is wrong but can't explain what, where, or when scores no better than one that simply missed the violation.
The joint metric therefore treats detection and reasoning as one combined decision:
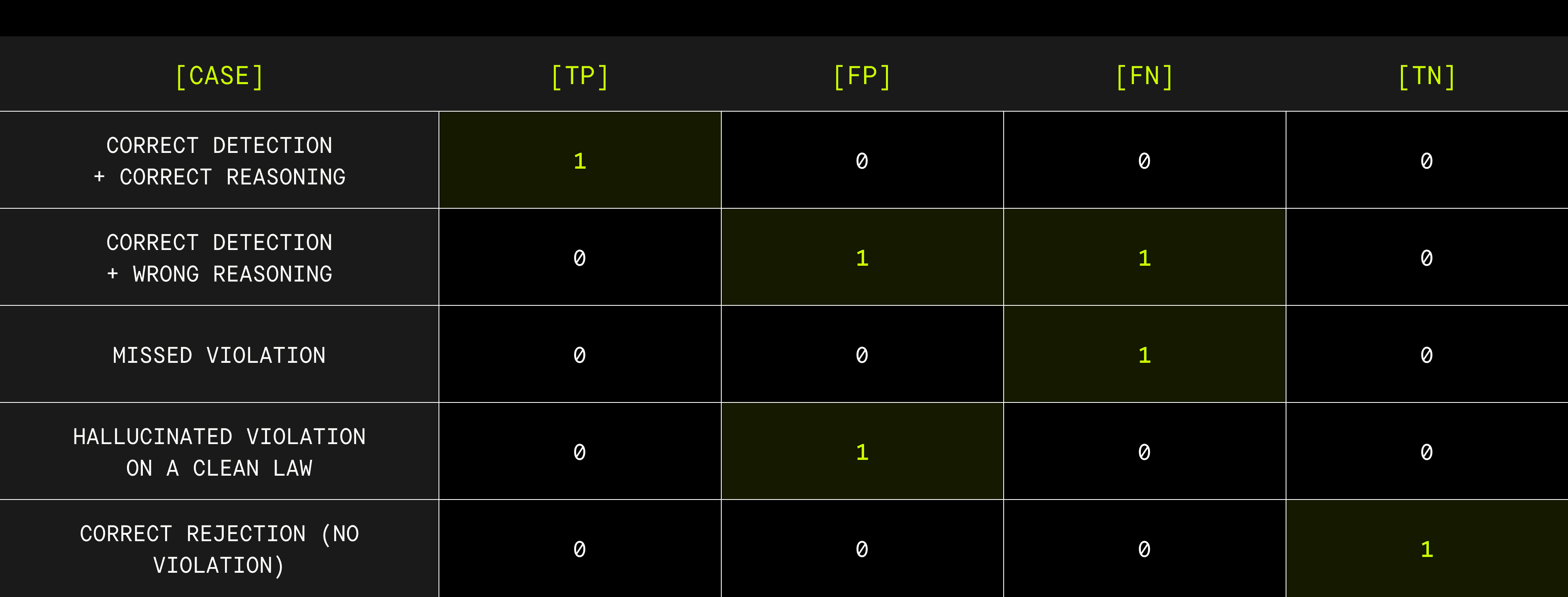
Why two levels? Level 1 isolates pure detection performance. Level 2 measures detection-plus-grounding, which is what we actually need from a physics critic. The gap between them tells you whether a model's failures are about finding violations or explaining them — and per-component breakdowns (object-match vs. frame-range-match) further localize whether the weakness is spatial or temporal.
Physical realism evaluation for video world models is not yet a solved problem — and existing benchmarks, while valuable, leave critical gaps in attribution, coverage, and methodology. With PhysicalRealismBench, we provide the community with a precise diagnostic tool: a benchmark with exact ground truth, an evaluation pipeline, and baseline results that others can compare against. Our goal is to make physics failures not just detectable but diagnosable — traceable to specific laws, objects, and moments. This initial release on physical understanding is the first step; generation and controllability tracks will follow. We believe this level of transparency is essential for building video world models that are safe and reliable enough for embodied deployment.
References: VBench (Huang et al., 2024), VBench-2.0 (Zheng et al., 2025), PAI-Bench (Zhou et al., 2024), WorldModelBench (Li et al., 2025), PhysBench (Chow et al., 2025), VideoPhy-2 (Bansal et al., 2025), PhyEduVideo (Mariam et al., 2026), Physion-Eval (Zhang et al., 2026, arXiv:2603.19607).
Author

Reka Team