Reka Flash: Efficient and Capable Multimodal Language Models
We introduce Reka Flash, our efficient, fast, and highly capable multimodal and multilingual language model.
Reka Flash is a state-of-the-art 21B model trained entirely from scratch and pushed to its absolute limits. It serves as the “turbo-class” offering in our lineup of models. Reka Flash rivals the performance of many significantly larger models, making it an excellent choice for fast workloads that require high quality. On a myriad of language and vision benchmarks, it is competitive with Gemini Pro and GPT-3.5.
Moreover, we also present a compact variant Reka Edge that is significantly smaller (7B) and more efficient, making it suitable for resource-constrained (e.g., on device, local) scenarios.
Both models are in public beta and available in Reka Playground right now! Try it here.
Meanwhile, our largest and most capable model Reka Core will be available to the public in the coming weeks.
Evaluations
Language
We evaluate our base models on three key benchmarks, i.e., MMLU (knowledge-based question answering), GSM8K (reasoning & math), HumanEval (code generation) and GPQA (Google-proof graduate-level question answering), a graduate-level question answering benchmark that is challenging.
Reka Flash achieves very strong results on these benchmarks. It outperforms Gemini Pro on MMLU and GPQA and is competitive on GSM8K and HumanEval. Moreover, Reka Flash is better than many larger models (e.g., Llama 2 70B, Grok-1, GPT-3.5) by a strong margin on these evaluations.

Comparison of Reka Flash against leading models on base language model evaluations. Most of the numbers above are self-reported with the exception of Gemini Pro on GPQA (we use their API) and Mixtral (we use the publicly released model). GPT-4 and Gemini Ultra are grayed out because they are in a different compute class.
Multilingual Reasoning
Reka Flash is pretrained on text from over 32 languages (see below) and is therefore a strong multilingual model. We compare models on three diverse multilingual benchmarks encompassing multilingual commonsense reasoning, causal reasoning, and question answering. Our results show that Reka Flash outperforms both Llama-2 70B and Mixtral on all of these tasks.

Languages pretrained on:
English, German, Chinese, Japanese, French, Korean, Spanish, Italian, Arabic, Hindi, Indonesian, Vietnamese, Thai, Czech, Dutch, Finnish, Bulgarian, Basque, Portuguese, Tamil, Persian, Greek, Russian, Turkish, Telugu, Burmese, Swahili, Urdu, Estonian, Malay, Swedish, Norwegian.
Vision and Video
We evaluate Reka Flash on a suite of multimodal benchmarks, including visual question answering (MMMU, VQA-v2), video captioning (VATEX), and video question answering (Perception Test). We find that Reka Flash is competitive to Gemini Pro on all four benchmarks.
For multimodal inputs, models deployed at Reka Playground work best in English at the moment.
Reka Chat Models
Reka Flash and Reka Edge base models are instruction tuned and then RLHFed with PPO using Reka Flash as the reward model. We conduct a series of human evaluations to evaluate our chat models.
We consider two setups, 1) text-only chat and 2) multimodal chat. Each setup has its own set of baseline models for comparison. We conduct blind evaluations with human raters from a third party data provider company. We compute ELO scores following Askell et al., where we only consider pairwise comparisons where annotators express a preference stronger than the weakest available. We report the overall win rate of each model against the rest together with ELO scores.
Text Chat
Our text human evaluation comprises over 1000 prompts designed to test model capabilities across diverse categories such as reasoning, coding, knowledge, input manipulation, and creative writing. We benchmark against leading models such as GPT-4, Claude 2.1, and Gemini Pro (API version). We also include Mistral 7B and Llama 2 7B chat for comparisons to Reka Edge.
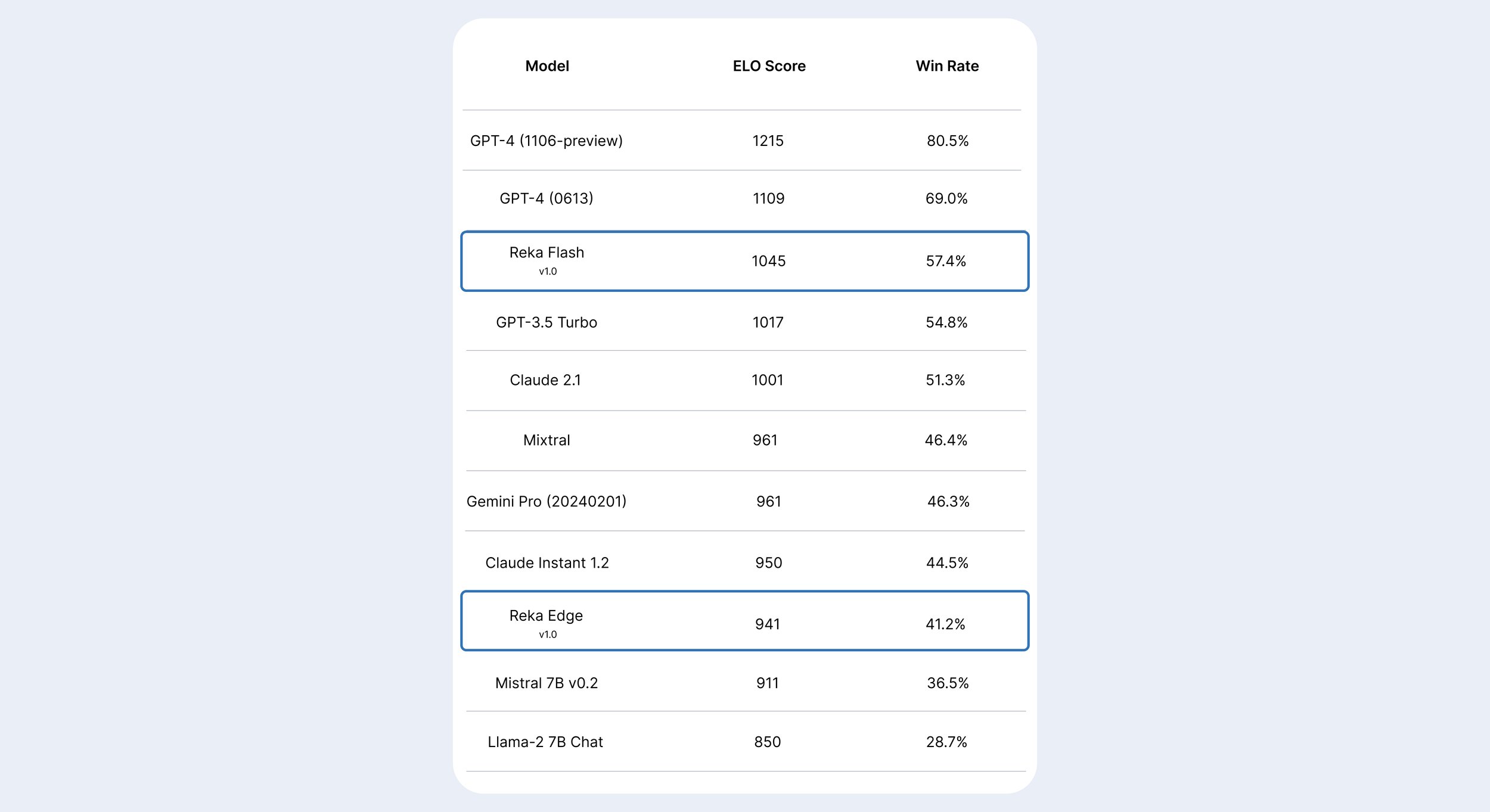
Our human evaluation results indicate that Reka Flash ranks competitively on our internal ELO leaderboard, outperforming GPT-3.5 turbo, Claude, Mixtral, and Gemini Pro. Reka Edge is ahead of the two other 7B models and comes close to Claude Instant 1.2.
While we generally do not recommend automatic evaluation based on proprietary models such as GPT-4, we check peak MT-bench scores of Reka Flash and Reka Edge. Reka Flash obtains a 8.2 MT-bench score, matching models such as Claude 1 and Claude 2. Meanwhile, Reka Edge obtains 7.6 MT-Bench score which is competitive with the best models of similar size in the industry. We find that models overfitted to MT-bench do not necessarily perform better on human evaluation. Therefore, we consider this benchmark inadequate and often misleading for model selection and measuring progress.
Multimodal Chat
Our multimodal chat evaluation measures the quality of a model’s response given an image and text prompt. We compare our models with multimodal language models such as GPT4-V, Gemini Pro, Llava-1.6, IDEFICS 80b, and Adept Fuyu-8B.
We design our evaluation prompts to be diverse and with moderate to hard level difficulty spanning many different categories such as food recognition, chart understanding, table understanding, humor understanding, shape detection, and others.

Our multimodal chat results show that Reka Flash outperforms all models except GPT4-V. Reka Edge also achieves a strong ranking, outperforming Llava 1.6 7B based on Mistral 7B and approaches the performance of Gemini Pro.
Reka Edge
Reka Edge is our compact 7B model designed for local deployments and latency sensitive applications. On language evaluations, we report its performance on language benchmarks compared to other models of similar scale, i.e., Mistral 7B and Llama-2 7B. Our results show that Reka Edge outperforms both Llama 2 7B and Mistral 7B on standard language benchmarks.

Concluding Remarks
Building state-of-the-art multimodal language models is at the heart of what we do. Reka Flash and Reka Edge represent initial milestones in our roadmap. We believe in the potential of AI to elevate humanity, and we are excited to continue pushing the frontiers of AI. Apply to join us here.
Reka Team
Aitor Ormazabal, Che Zheng, Cyprien de Masson d’Autume, Dani Yogatama, Deyu Fu, Donovan Ong, Eugenie Lamprecht, Eric Chen, Hai Pham, Kaloyan Aleksiev, Lei Li, Matt Henderson, Max Bain, Mikel Artetxe, Nishant Relan, Piotr Padlewski, Qi Liu, Samuel Phua, Yi Tay, Yuqi Wang, Zhongkai Zhu