
A world model is a learned model of an environment's transition dynamics: given the current state of the world and an action, it predicts the next state and optionally, the reward. By rolling it forward, it can predict how the world evolves under a sequence of actions. In pixel-based settings the state is not directly observable, so the model maintains an internal state, inferred from the observation history. Put simply, the agent uses its internal model of the world to predict the consequences of different actions, then commits to a selected action, executes it, and collects observations, which are then used to estimate the world state.
Agents use world models as substitutes for the environment itself, usually:
as a planning substrate (model-predictive control over imagined rollouts)
as a training environment (policy optimization in imagination)
as lookahead at deployment time
All of these applications rest on one assumption: under the same actions, trajectories inside the model are distributed like trajectories in the real environment.
That assumption is rarely tested directly. Current evaluation asks whether generated rollouts look plausible, or whether a planner reaches goals inside the model. Neither measures what happens to an agent whose decisions depend on the model's predictions.
WorldModelGym is a benchmark built around that missing measurement. It evaluates behavioral fidelity: how much of an agent's performance in the real environment survives when the agent's perception is replaced by the world model's predictions.
How world models are evaluated today
The first family of evaluations scores the generated video itself: visual quality, physical plausibility, instruction following (VBench, VideoPhy, Physics-IQ, WorldModelBench, WorldScore). These measure the marginal plausibility of rollouts, with no action conditioning and no comparison against the trajectory the real environment actually produced. The gap this leaves is documented: Physics-IQ found visual realism to be largely uncorrelated with physical understanding.
The second family uses the model for control and reports task success. stable-worldmodel is the strongest version of this: a model-predictive-control planner optimizes action sequences inside the world model, and planning success rate is the score. This is the right test for planning research, but it constrains what can be evaluated. The model must expose a cost function over its internal states, which excludes generative video models that produce only pixels. Task success also conflates two quantities: the model's fidelity and the planner's capacity to exploit model error, a well-documented failure mode in model-based RL. And the compute is substantial: a sampling-based planner evaluates on the order of 10⁴ candidate rollouts per control step, where our protocol costs one model forward pass per real step.
What neither family measures is the consequence of trusting the model: fix an agent, condition its perception on the model, and observe its performance in reality.
The protocol: act in reality, observe the imagination
Let π be an evaluation policy mapping observations to actions, trained to competence on the task and then frozen. WorldModelGym rolls out π twice.
Direct rollout. π interacts with the real environment in the standard way, observing real frames. Its mean episodic return over N seeded episodes, R₁, is the baseline.
Coupled rollout. π plays again, and its actions still execute in the real environment, but its observations now come from the world model. The model's state is initialized from the same seed observations, the action a_t = π(ô_t) is computed from the model's decoded observation ô_t, and the same a_t is executed in both the real environment and the model. The real environment's return under this control loop is R₂. Every step is:

The headline score is return retention, R₂ / R₁: the fraction of its real performance the policy keeps when it observes only the model. A model with accurate transition dynamics leaves the policy's behavior unchanged and retention near 1. Systematic errors, an object in the wrong place, a reward at the wrong step, an episode that terminates in the model but not in reality, pull the executed trajectory off the policy's competent distribution and retention drops. The evaluator records per-step diagnostics alongside the ratio, including the gap between predicted and realized rewards and the step at which the two trajectories separate, which localize where a model breaks down.
When the environment's transition kernel is stochastic, open-loop prediction of one realized trajectory is ill-posed: the model can sample a valid future that is not the future the environment drew. The protocol accounts for this with re-anchoring. At a fixed, benchmark-owned interval, the model is handed the realized observation history up to the current step and updates its internal state on it. Realized observations are the only information that flows back into the model, and the observation the policy acts on is always the model's own prediction of the step ahead. The divergence reduction after each re-anchor is recorded, so how well a model re-synchronizes is itself measured.
Here is a coupled rollout on Acrobot: the real environment on the left, a world model's prediction of the same episode on the right, with each side's cumulative reward overlaid.
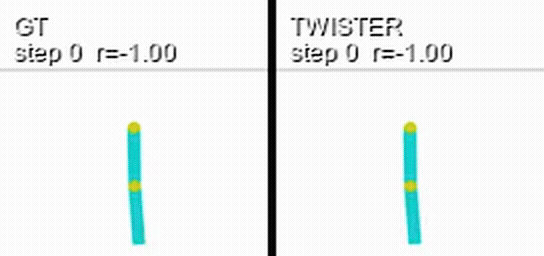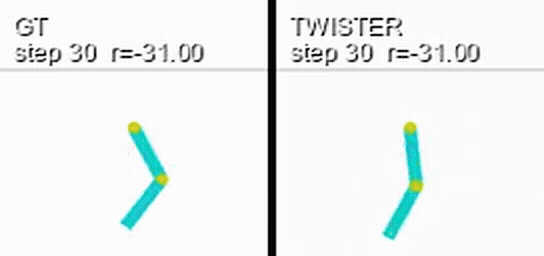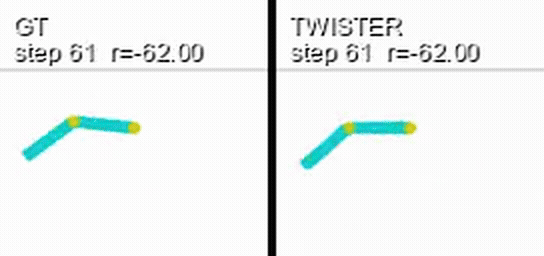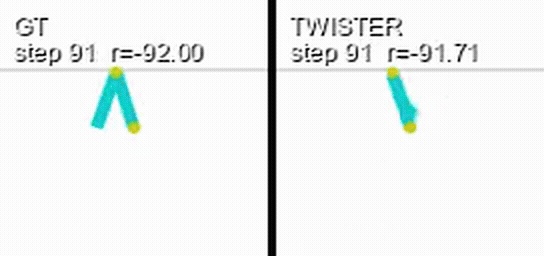
Retention is uninformative under an incompetent policy: a random policy achieves the same return distribution no matter what it observes. Each track therefore ships a pretrained, frozen evaluation policy owned by the benchmark. Submitters do not choose the policy, which keeps the comparison identical across models.
What a model has to implement
Gymnasium standardizes the agent-environment interface. It has no contract for a learned simulator. WorldModelGym defines one:
step mirrors gymnasium.Env.step: it returns the next state plus gym-style reward and termination fields. Predicting reward is optional. The headline retention score is computed from real-environment rewards only, so a model that does not model reward can return zero; only the reward-mismatch diagnostics use the predicted value. The model consumes actions; it never selects them. State is explicit and opaque to the evaluator: passed in, returned, never inspected. That makes rollouts replayable and branchable, and places no constraint on the representation, whether latent vector, token sequence, or pixel buffer. A wrapper exposes any WorldModel as a standard gymnasium.Env, so existing rollout tooling works on both sides.
There is no cost function and no access to internals. Latent dynamics models, pixel-space predictors, and generative video models all fit the same contract, and the last group is the one that planner-based evaluation cannot accommodate at all.

To our knowledge, no existing benchmark replays an identical action sequence through both the model and a live ground-truth environment and scores the behavioral consequences.
stable-worldmodel is the closest neighbor, and the two benchmarks are complementary rather than competing. It measures whether you can plan inside a model; WorldModelGym measures whether the model behaves like reality when something acts on it. Their paper notes that a model can appear successful on standard benchmarks while misrepresenting the underlying dynamics, and that is precisely the gap behavioral fidelity is designed to expose.
Why a benchmark and not a metric
World model evaluation is fragmented the same way world model research is. Each paper measures its models in its own setup: different environments, different observation sizes, different horizons, different policies, different definitions of error. The resulting numbers do not transfer across papers, and protocol choices that look minor, such as who controls the policy or how long the rollout runs, move them substantially.
The dominant proxy is also confounded. When the scored agent was trained inside the world model, in the imagination-training setup, the agent co-adapts to the model's errors: it learns to avoid the regions of state space where the model is wrong, and return stays high while the dynamics remain untrustworthy. The protocol above removes that freedom. The policy is fixed before the world model enters the picture, and reality does the scoring.
Comparability is the rest of it. Per track, WorldModelGym pins the evaluation policy, that policy's real-environment baseline (computed once and reused for every evaluation), the observation format, the episode budget, and the score range used to normalize returns. Two world models evaluated months apart face the same task, the same behavior, and the same reality.
What's in the benchmark
WorldModelGym launches with 125 tracks across six environment families: 49 Atari games, 50 Meta-World manipulation tasks, 19 DeepMind Control tasks, classic control, Box2D, and MiniGrid.

Environment choice is part of the benchmark design, because a good RL task is not automatically a good world-model benchmark. The suite favors environments that are observable from a fixed observation-history window, reset reproducibly with controlled stochasticity, and run horizons long enough for compounding prediction error to matter. Each track is a single declarative file that pins the environment, the canonical observation, and the scoring range, so extending the suite does not touch the evaluator.
A world model connects through a small adapter that implements the interface above. Adapter conformance checks and a canonical result format keep submissions comparable. The leaderboard lists all tracks, each with a preview of its evaluation policy acting in the ground-truth environment and its baseline score.
You can find the leaderboard here. For evaluation requests or questions: [contact].
Author
