
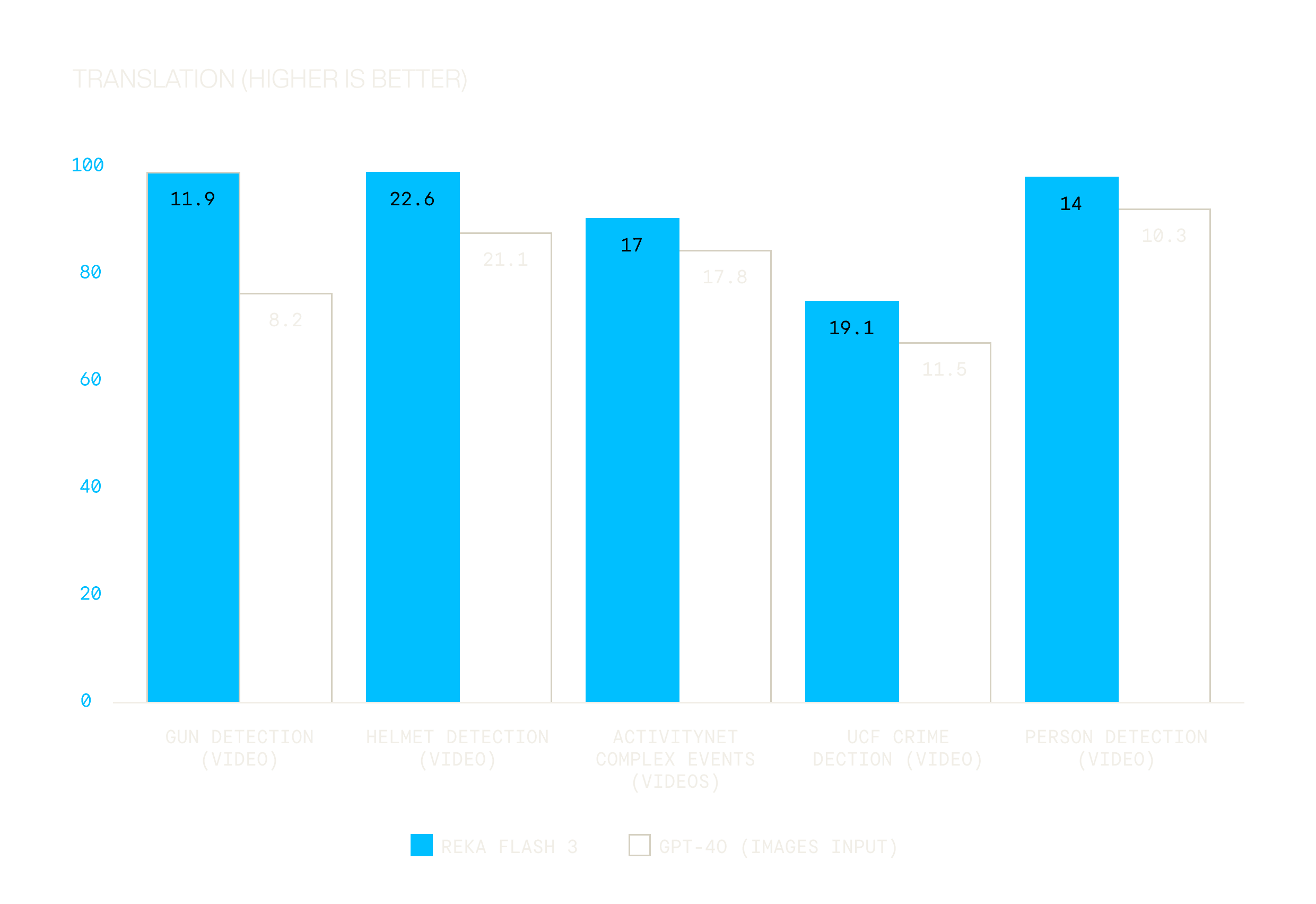
At Reka, our goal is to develop multimodal AI that truly understands the physical world. Vision capabilities are core to our mission. With Reka Flash 3, we have built a multimodal language model that goes beyond simple image understanding and is broadly capable of real-time video understanding in multiple domains, surpassing advanced models such as GPT4o. Trained from scratch with our proprietary technology on millions of hours of licensed videos, billions of images, and trillions of text tokens, it is applicable for many industries including manufacturing, agriculture, security, and many others.
I. Unlocking the Power of Real-Time Visual Intelligence: Results from Different Domains
Traditional computer-vision models analyze frame-by-frame and provide a snapshot in time. In contrast, our model looks at a longer horizon. It identifies objects, tracks their movements, and analyzes interactions to make sense of complex events in real time.
In internal evaluations, we found that our model is better than GPT 4o at video understanding for real-world scenarios. Below are a few examples that show how our AI makes a real difference.
Public safety: detect guns, trespassers, fights in schools and other crowded public places.
Factory and warehouse: identify issues with worker’s safety, problems in assembly line, and inventory management.
Media: find highlights, detect emotions, create video summaries, and search across many videos.
II. Multimodal Architecture

In order to reason over a video input, our model uses multiple frames (sampling them as needed), treat each frame as an image and split it into patches to handle arbitrary resolutions, and feed it into a transformer-based vision encoder to produce visual features. These visual features are combined with textual and audio features in an interleaved fashion by a backbone multimodal language model to generate outputs.
This architecture allows our model to:
Detect events that happen in real time by asking it to trigger an alert when it observes a specified event.
Search over a large collection of video databases using a combination of keyword-based (with dense captioning), vector-based (with text-image embeddings), and multimodal language model based searches.
We found that our multimodal language model can be combined with with traditional computer-based object detection models to build a very accurate video search and real-time video monitoring solutions.
III. How We Can Help Your Business
We are constantly improving our collection of visual language models and optimizing our infrastructure to serve them with low latency. We help enterprises and government organizations automate tasks, get new insights, and make faster decisions. You can try our multimodal model at Space or use it via our API. If you need an AI that truly understands the physical world, contact us for a demo.
Author
