
We are excited to announce Reka Speech, a 850 million parameter model designed for multilingual speech-to-text and speech-to-speech translation. It consists of a 550M transformer decoder and a 300M audio encoder. It understands English, Japanese, Korean, Chinese, French, Spanish, German, Italian, Portuguese, Arabic, and can translate from English to any of the other languages and vice versa.
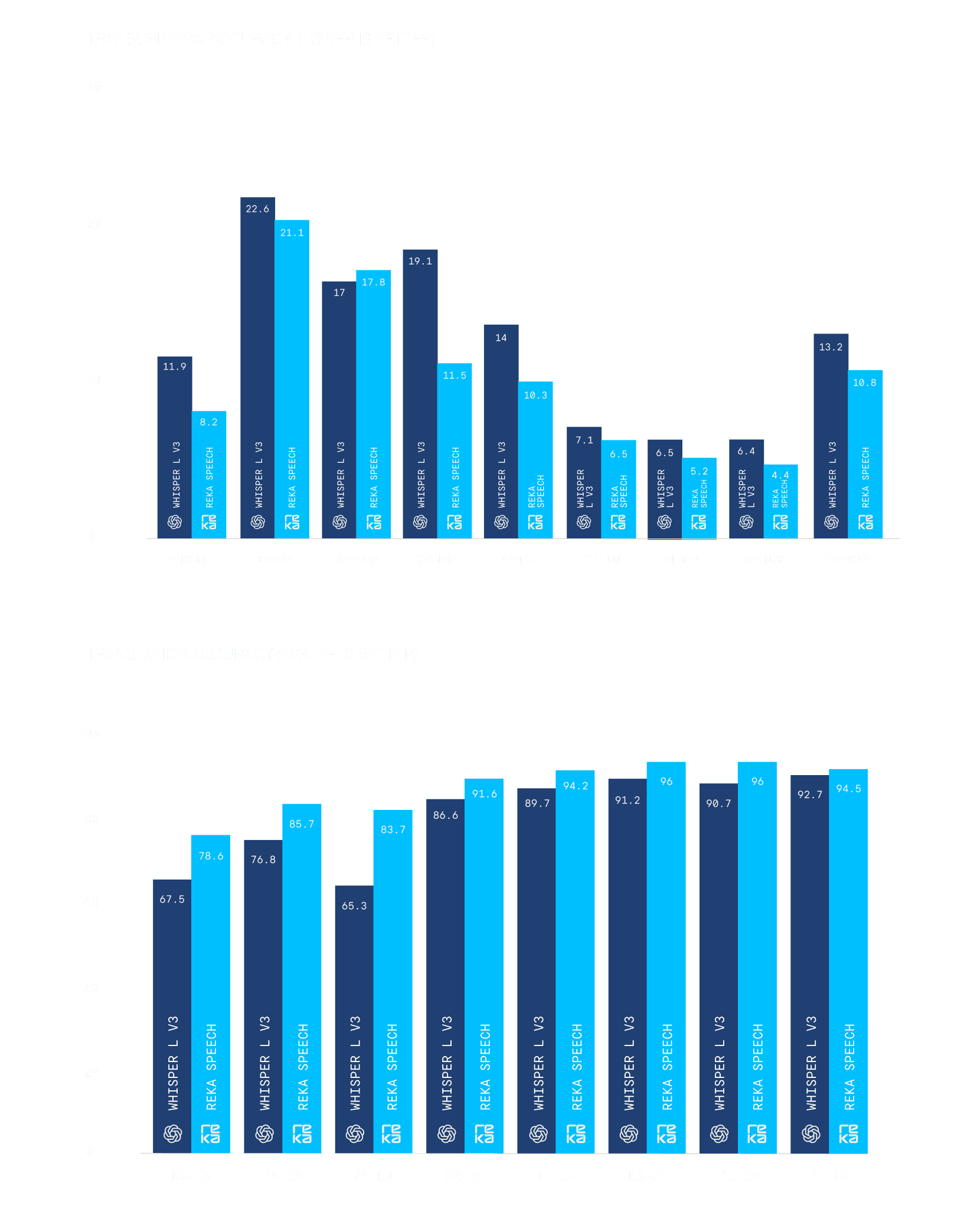
It outperforms popular open source models such as Whisper-L v3 on commonvoice16.1 (transcription) and our internal translation dataset.
In addition to the real-time setting, Reka Speech is uniquely suitable for high-volume offline audio transcription and translation jobs. For example, given millions of hours of videos, we want to transcribe and translate their audio tracks with timestamps. This is a recurring use case we often hear from enterprises for adding subtitles, chapterization, or supporting better search.
Existing solutions for speech-to-text with timestamps include:
WhisperX, which combines an ASR model for transcription with a wav2vec alignment model for word-level timestamps.
OpenAI Whisper, which derives timestamp information by integrating sentence-level timestamps from model output with token-level timestamps from the attention-weight matrix.
Faster-whisper, which employs a similar approach to OpenAI Whisper but uses VAD for sentence-level timestamps.
Other CTC-based and transducer models which are trained for timestamp alignment.
None of these approaches is optimized for high throughput, particularly on modern GPUs with larger memory. They are often designed for demo purposes or edge device deployment.
Our efficient method relies on a modified vLLM for rapid inference. During the forward pass, we offload self-attention query and key embeddings to CPU memory (QK cache). After the transcript is generated, we move them back to GPU and recompute attention weights. We then use dynamic programming to find the highest scoring alignments of the input audio and generated transcript tokens. See illustration below for more details.

We compare the processing speed of our 850M parameter model to three existing solutions based on Whisper-Medium (769M parameters). These tests were conducted on a single H100 GPU using 16,390 audio files (the test subset of commonvoice 16.1 en). Our inference method allows us to process this dataset 8x-35x faster compared to alternative methods. This directly translates to meaningful cost saving for our customers, especially at the volume of data they are working with.

Efficient training and inference is core to our mission at Reka. If you are interested in advancing the state-of-the-art on model efficiency, apply to join us here. If you want to transcribe or translate a large amount of audio data with Reka Speech, please contact us.
Author
