Reka Responsible AI, Model Risk, Ethics & Governance Framework

We release Reka Flash Quantized, a 3.5-bit quantized version of Reka Flash 3.1 that delivers state-of-the-art performance at low bitwidths, together with Reka Quant, an open-source version of our internal model quantization library. Reka Quant is compatible with any quantization primitive and leverages calibrated error reduction together with direct self-distillation to deliver state-of-the-art performance at low bitwidths. This blogpost details our approach to low bitwidth model quantization.
Quantization primitives and error reduction
Most quantization approaches can be characterized by the quantization primitive and the error reduction techniques they use.
The quantization primitive is the quantization function itself, that takes a minimal block of numbers and maps it to a representation in the quantized datatype. In other words, the quantization primitive “rounds” the numbers to their quantized versions. This depends on the quantized datatype, as well as grouping strategies used to chunk numbers together to be quantized with the same quantization scales. For example, bitsandbytes NF4 utilizes a special 4 bit datatype (NormalFloat) with hierarchical grouping, while popular K-Quant methods from llama.cpp utilize common integer datatypes, and also employ hierarchical groups (or superblocks).
In addition to the quantization primitive, a variety of error reduction techniques can be used. These techniques modify the weights of the neural network to make them more compatible with the quantization primitive. In other words, these techniques modify the weights in such a way that the model performs better after applying the quantization primitive. One type of error reduction techniques are calibration based approaches, that leverage precomputed activation statistics to minimize a proxy error when quantizing: popular examples include imatrix calibration in llama.cpp, or the LDLQ method from Chee et al. Another powerful class of error reduction methods are training based approaches, such as layer-wise finetuning (an example is Tseng et al.), or quantization-aware training (QAT).
Reka Quant
Reka Quant disentangles these two aspects of quantization, making it compatible with any quantization primitive in principle, and employs a simple but powerful approach to error reduction. Our released open-source codebase supports exporting to the popular 3.5 bit Q3_K_S format from llama.cpp, and can be readily expanded to other llama.cpp datatypes through C bindings.
For error reduction, we combine two powerful techniques:
LDLQ error reduction leverages precomputed activation statistics to reduce quantization error of each linear layer individually. More precisely, LDLQ aims to reduce the quantization error for each specific weight tensor by minimizing the proxy loss ℓ(Ŵ) = 𝔼ₓ [‖(Ŵ – W) x‖²], where W is the original weight matrix and Ŵ is the quantized matrix. To this end, weights in W are quantized column by column, and the remaining unquantized part of the matrix is updated with linear feedback from the quantization error of the first columns). LDLQ is provably optimal among a certain class of error reduction methods that employ this linear feedback approach. Since the proxy loss has to be computed and minimized over a certain calibration set, LDLQ requires pre-computing some statistics of the network activations at each layer over this set of inputs (namely the proxy hessians, 𝔼 [x · xᵀ])
Full network self-distillation: In addition to reducing error at the linear layer level through LDLQ, we employ self-distillation at the logit level with the full-precision BF16 neural network. We start from the unquantized model, and gradually quantize tensors one by one, while recovering lost performance through self-distillation throughout the process. After each tensor is quantized, its weights are frozen and the rest of the network continues to be trained normally. Crucially, this distillation is performed on the full network, allowing our approach to account and correct for inter-layer dependencies effectively.
Since LDLQ requires activation statistics from the current model, combining it with self-distillation poses a technical issue, as it modifies the weights in between quantizations, making it impossible to precompute these statistics from the original unquantized model. We resolve this by computing the statistics online right before each quantization, leveraging fast distributed Hessian computation on GPUs to reduce computation time.
While calibration based techniques such as LDLQ are powerful, they operate on a single tensor at a time and cannot take into account inter-layer interactions introduced by modifying weights in each tensor, and cannot leverage increased data and compute for better performance. Self-distillation is a powerful way to reduce quantization error at the network level, and, crucially, we find it scales well with compute.
Why not QAT?
While QAT can be a powerful error reduction technique, it needs to quantize and dequantize every weight in the network at each forward pass, which limits the space of quantization techniques, as it must be very fast to be feasible. However, error reduction methods such as LDLQ, or quantization datatypes that are more expensive to compute (such as K-Quant based Q4_K instead of Q4_0 in llama.cpp) that greatly improve performance are in practice too slow to incorporate into QAT. In our experiments, we find that performance gains from these slower quantization approaches are large enough that QAT cannot recover them with cheaper datatypes even after thousands of steps. In contrast, our self-distillation trains the model normally in between quantizations, and thus can be integrated into any existing quantization primitive.
Performance
We apply Reka Quant to our latest reasoning model, Flash 3.1. We train for 1800 total steps, dividing all tensors to be quantized into 7 groups.¹ We find that, even when training for only 1800 steps (less than 0.1% of the pre-training budget) Reka Quant achieves near lossless quantization to 3.5 bits when quantizing to the popular Q3_K_S datatype in llama.cpp, incurring only a 1.6 point avg degradation in hard reasoning benchmarks, and a 1.9% increase in perplexity on a validation set composed of reasoning data. llama.cpp’s imatrix based Q3_K_S quantization routine, on the other hand, incurs a 5% increase in perplexity, and a 6.7 average degradation on benchmarks.
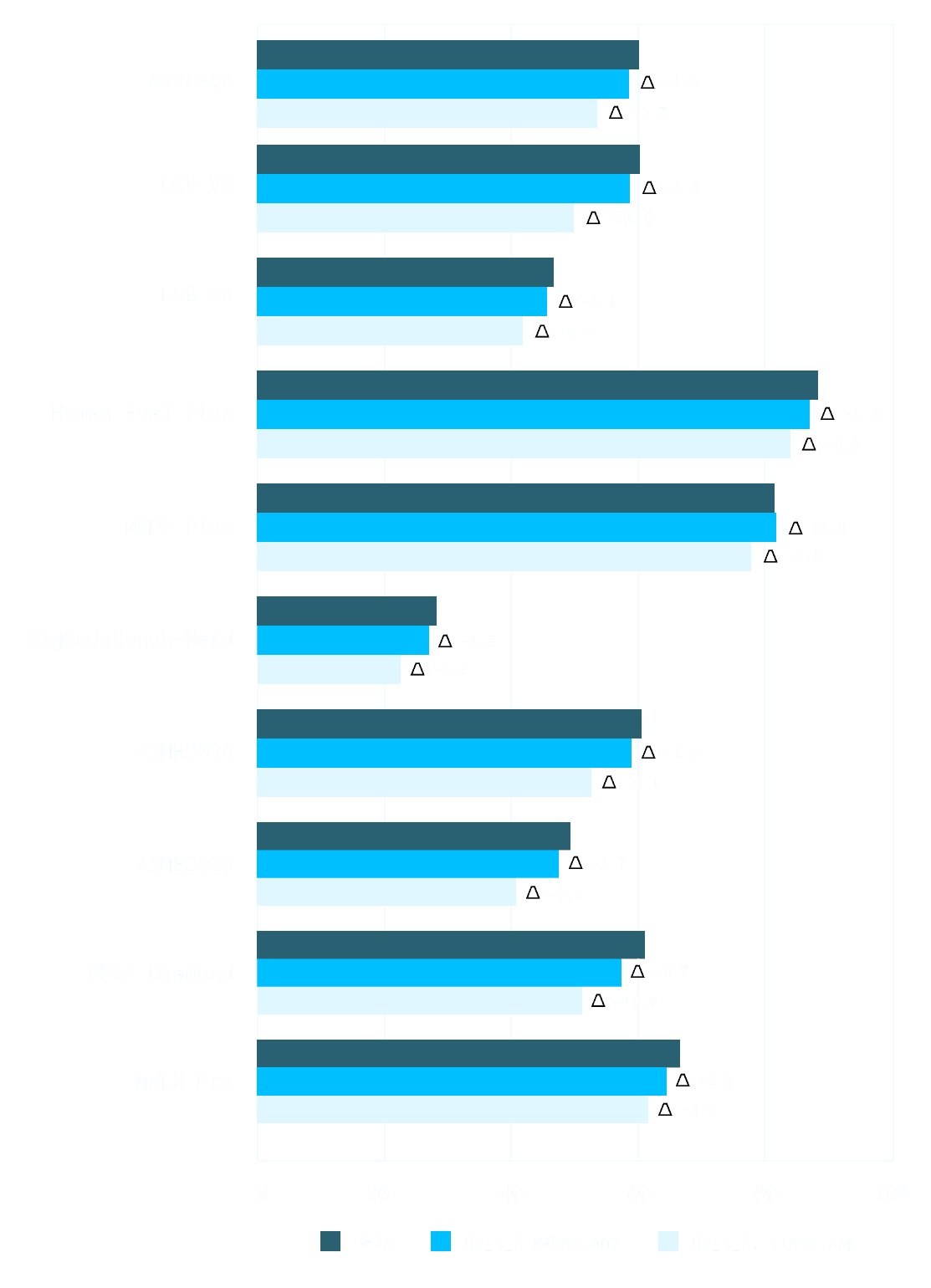
Reka Quant incurs less than 25% of the average benchmark degradation of llama.cpp, at the same bitwidth
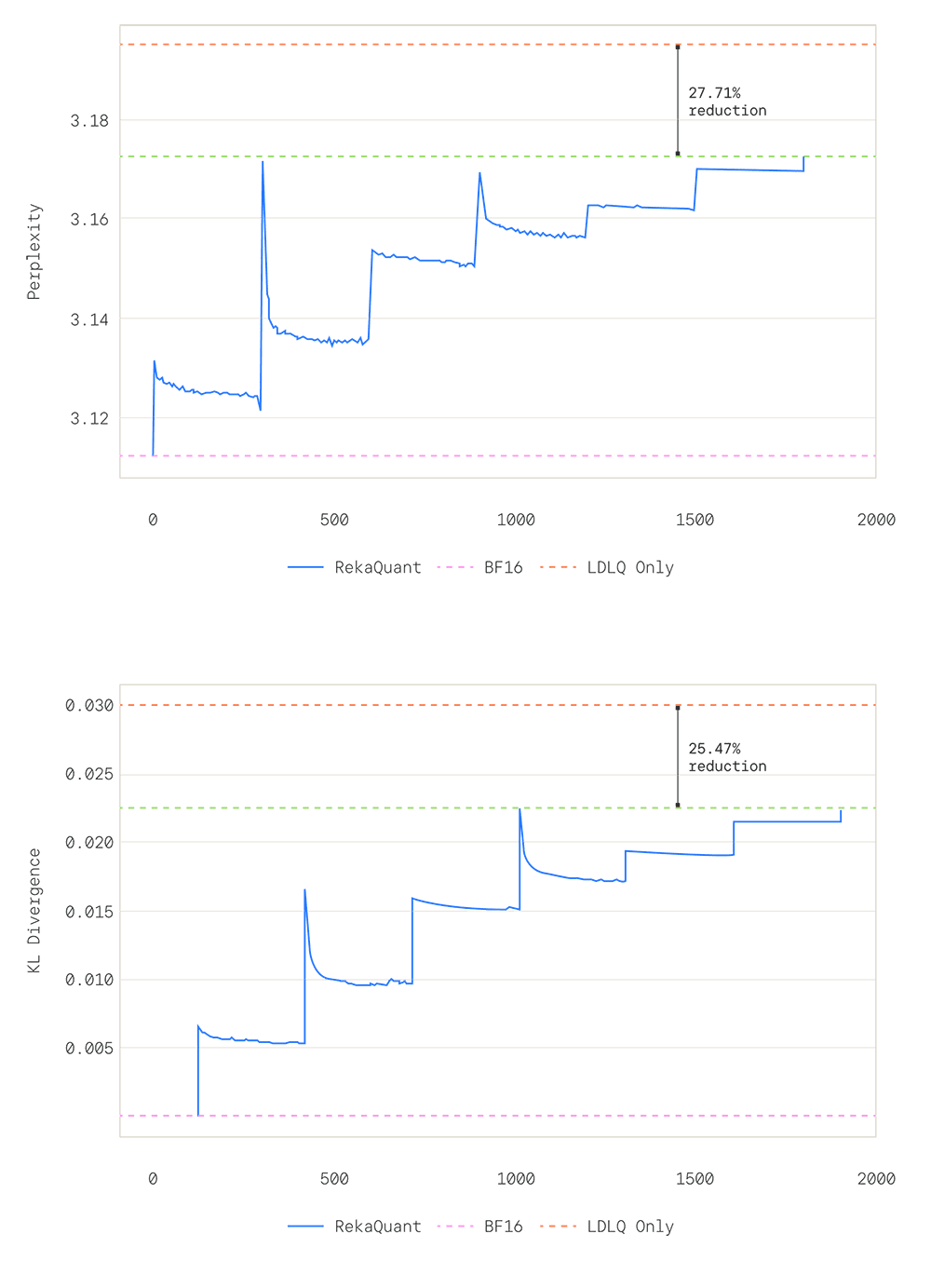
Our self-distillation strategy is also effective at recovering lost performance, achieving a 27.7% reduction in perplexity degradation and a 25.5% reduction in KL divergence over the BF16 model at 1800 steps, compared to a strong pure LDLQ baseline (compared to the native llama.cpp baseline, the reduction in PPL degradation is 67%). Additionally, we find in our experiments that the benefit from self-distillation increases for more aggressive low-bitwidth quantization, and improves predictably with increasing compute.
Releasing our quantization stack
To support further research on quantization by the community, we release an open-source version of our internal quantization stack. This library supports self-distillation, fast distributed proxy Hessian computation for fast LDLQ, and exporting to the popular Q3_K and Q4_K datatypes in llama.cpp. The codebase can be found on our github.
––––––––––––––
1. For each group, we quantize every tensor of the same kind in each layer. Our chosen order is as follows:
Group 1: FFN up
Group 2: FFN gate
Group 3: FFN down
Group 4: Attn values
Group 5: Attn projections
Group 6: Attn keys, Attn values
Group 7: Embeddings and LM head
For the released Q3_K_S quant of Flash 3.1, we follow a simple heuristic to choose this quantization order, quantizing the tensors that incur the highest loss in performance first.
Author
