
In today's data-driven business landscape, we often face a common yet complex challenge: retrieving critical information buried in unstructured or semi-structured formats. For example, you have been tasked to find out what your organization’s profit margins are for the past year. The answer lies within your company's financial data, but there's a catch – it's hidden in a chart and table, nestled deep within a 200-page PDF report.
This scenario highlights critical limitations in many of today's information retrieval systems when dealing with unstructured, multimodal data, particularly those employing Retrieval-Augmented Generation (RAG). Here is an article describing how RAG works
Heavily optimized for text: The vast majority of information retrieval systems (particularly RAG-like systems) still only operate on text only. Yet 80% of the world's data is multimodal.
Embedding model limitations: Traditional image embedding models (e.g., CLIP) are not designed to handle the type of unstructured data that is common in business settings. They understand the difference between a cat and a dog, but they cannot understand the difference between two tables in a financial document.
Close connections between modalities: Back to our previous example, processing real-world business data in RAG systems is extremely challenging, because data of different modalities are often tightly coupled in practice. For example, eCommerce web pages include both text descriptions and images and financial reports have texts that refer to specific tables and charts which by themselves only include partial context.
With the help of Reka’s multimodal AI, you can overcome these challenges and truly unlock the potential of unstructured and multimodal data for your business. Reka offers a family of 4 models of different sizes (accessible via API or our on-prem/on-device deployment solution). These models are trained from scratch, and have state-of-the-art performance for business relevant benchmarks.
In the rest of this blogpost, we will demonstrate how Reka’s multimodal AI and MongoDB Atlas can be used together to make your business’ unstructured data searchable and useful in RAG-based AI applications.
Unstructured multimodal data to insights
The easiest way to unlock maximum value for your unstructured business data (video, images, audio, PDF documents) is to use Reka’s models to convert it to structured format. In this blogpost, we will go over two of these examples.
Chart to structured text
In this example, we demonstrate how we can use Reka’s models to convert chart images directly to markdown, store them in MongoDB Atlas Database, and perform analytics on them.
Set up the environment
Register for Reka API.
If you haven’t already, register for a MongoDB Atlas account
Set up a cluster following the steps in here.
Install Python dependencies
We need reka-api and MongoDB Atlas libraries for this demo.
$ pip install reka-api pymongo[srv]
Calling Reka API
We use Reka API to convert chart images to text markdown. For this demo, we choose a reka-core model (reka-core-20240501) from the list of available models.
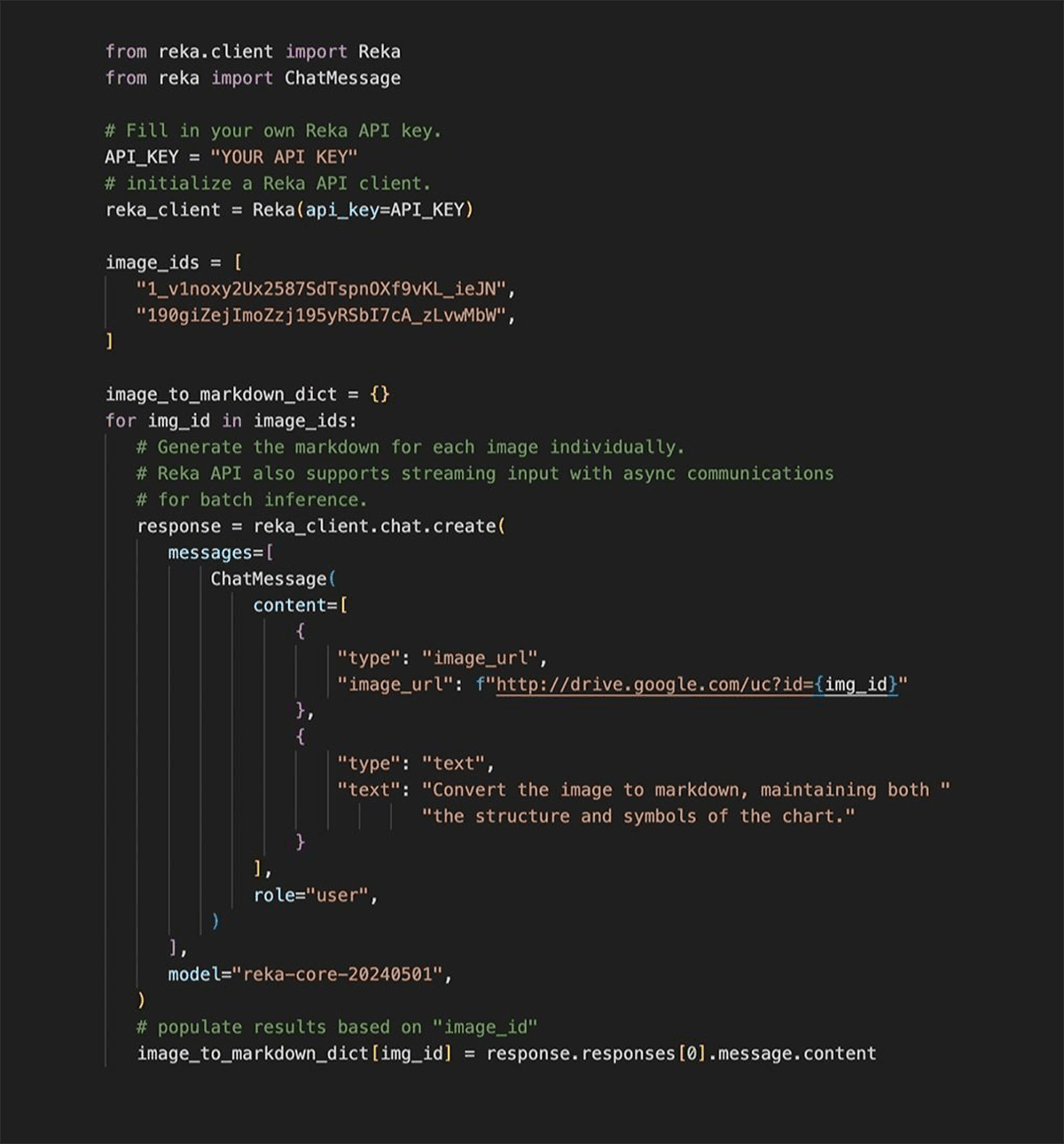
Visualize the input and output with the following code:

Running the code above produces the following result:


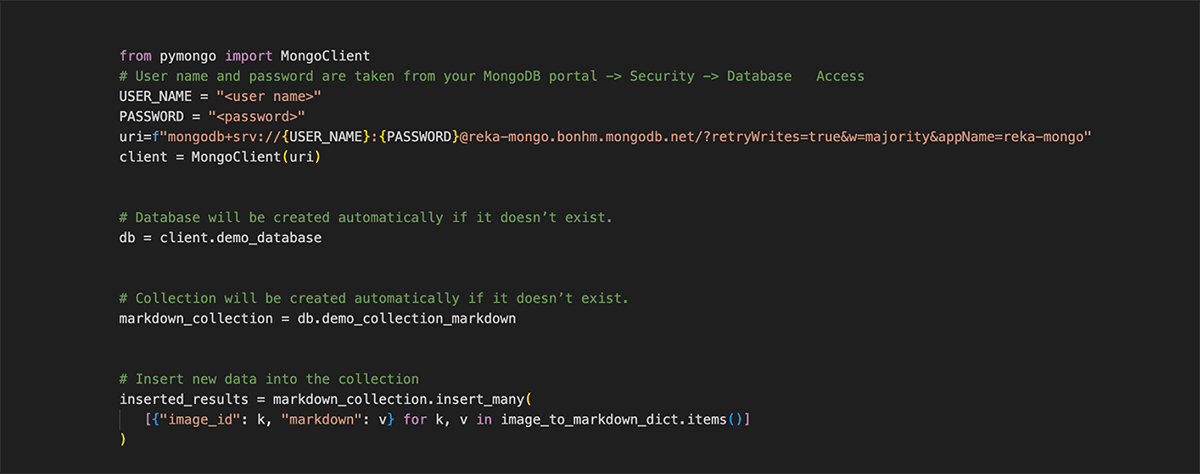
Store results in Atlas
Create a MongoDB Client then store our results into a database collection
Search
Once the charts are converted to a text format, they can be indexed by MongoDB Atlas for search.
First, create a search index:

Second, define a search method:

Perform lexical search:

The result:
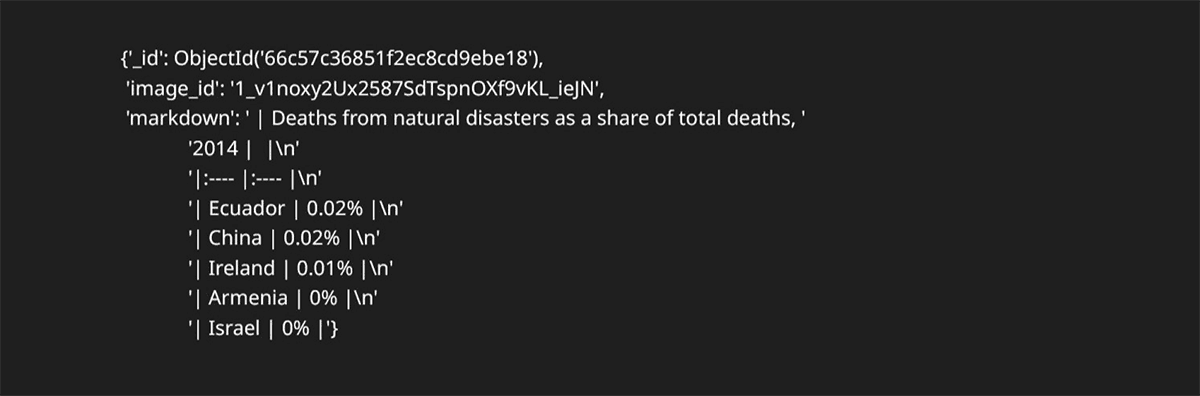
Augment charts with AI generated descriptions
Another way to add value to charts and tables is to use Reka’s models to generate detailed descriptions for them. This is as simple as changing the prompt of our previous example.
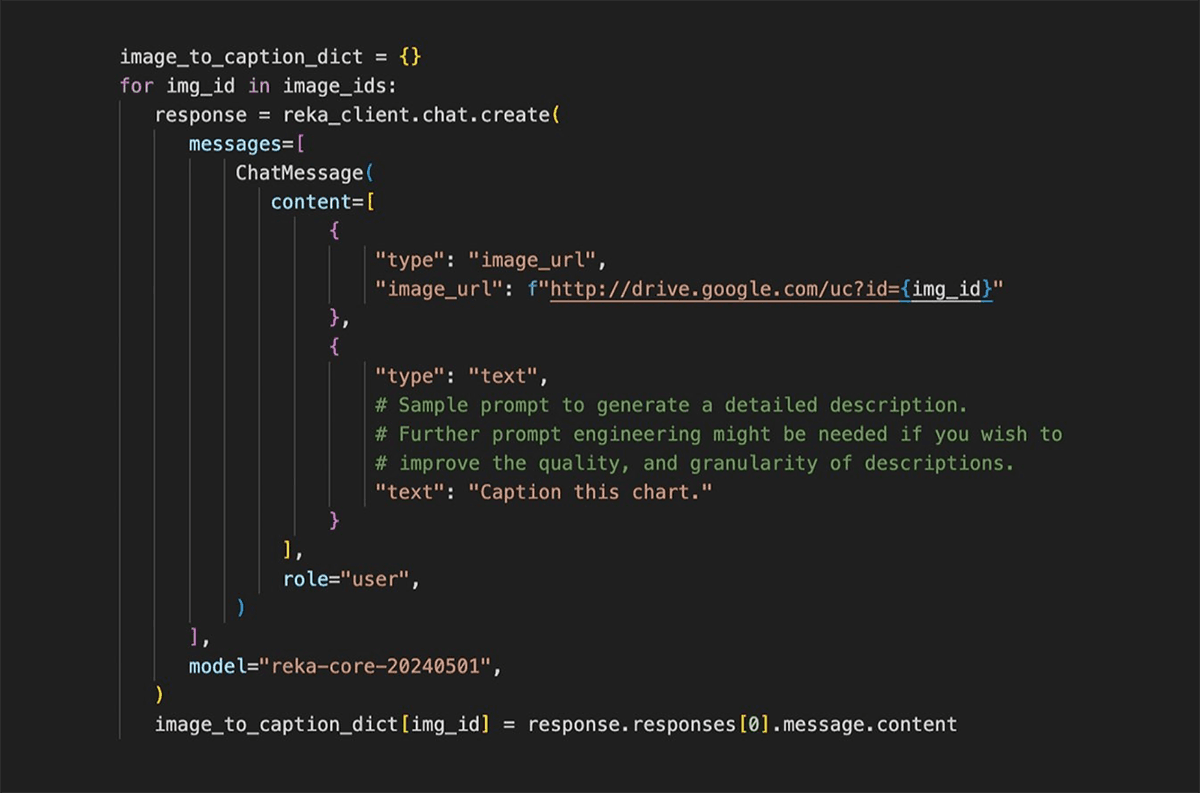
The result below demonstrates that Reka's models generate descriptions with a level of detail that indicates an advanced understanding of the input charts. This goes well beyond the capabilities of conventional OCR and PDF parsing tools.
Same as before, output from Reka’s models can be indexed and searched using MongoDB Atlas.
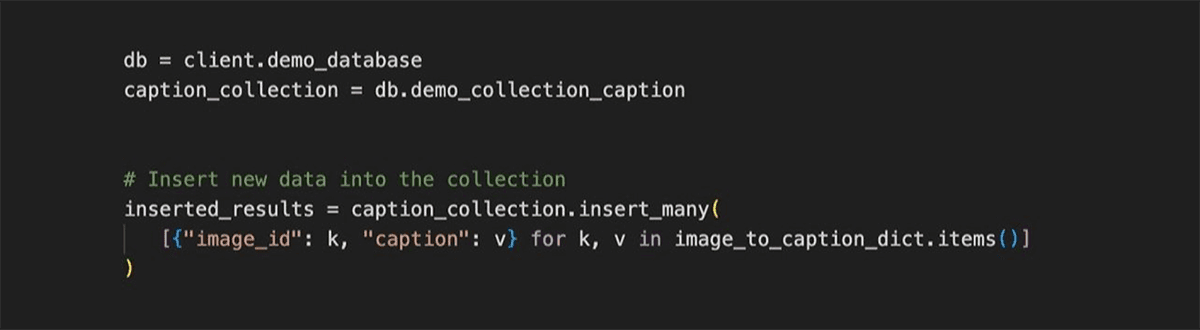
Create an index using this new collection

Then we can use a keyword to search for relevant image based on its description, e.g.

The result should retrieve the respective record

2. Video to structured text
Reka’s models support a wide-range of unstructured data types including image, audio, and video. More information can be found in our API documentation.
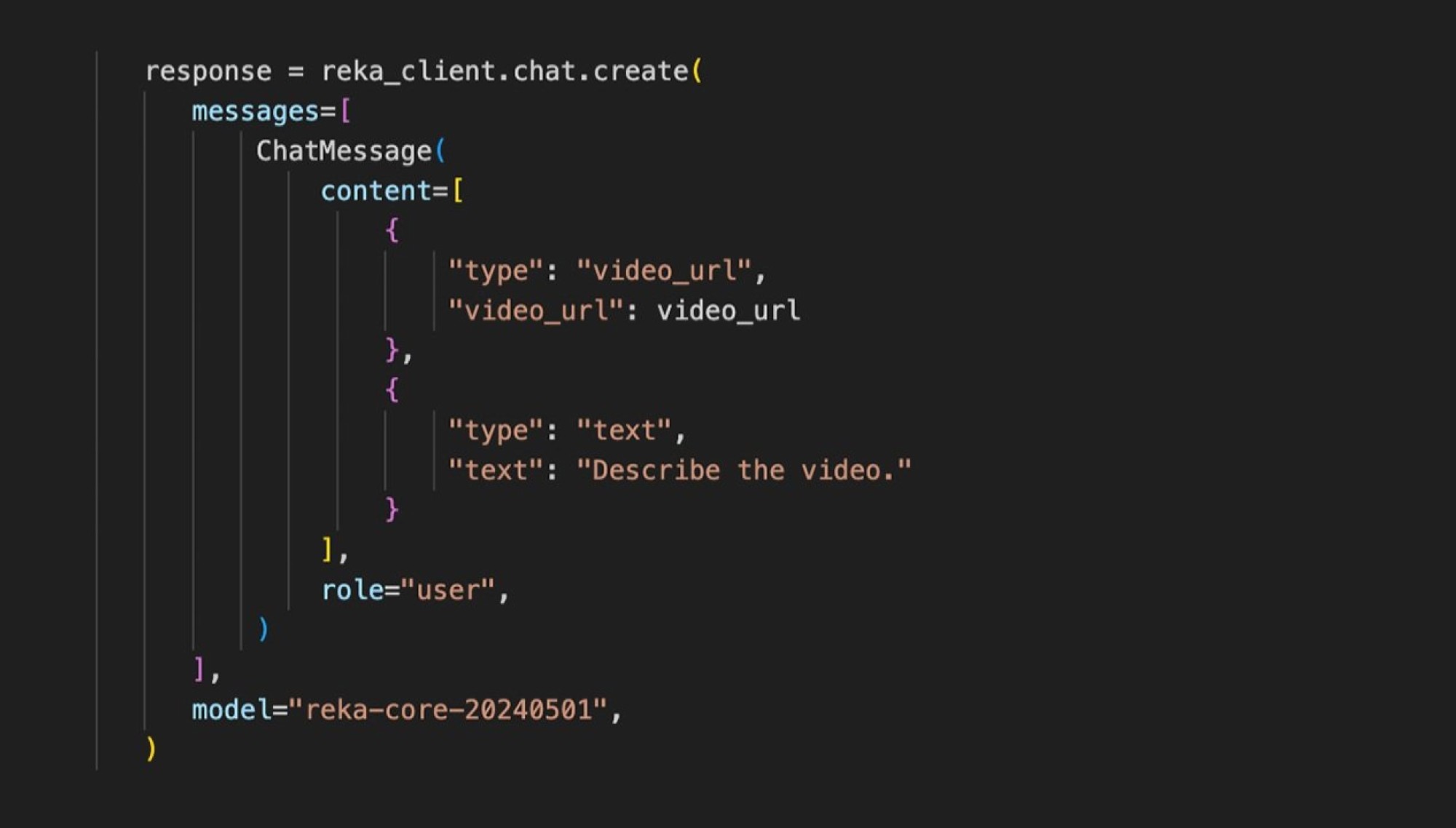
We can extend the previous example to support video data as well.
This is as simple as changing the type parameter of chat.create from image_url to video_url.
Reka’s RAG optimized multimodal language models
Besides using Reka’s models to convert unstructured data to text, another way to maximize the value of unstructured data in Generative AI applications is by integrating Reka’s model directly into your RAG workflow. Reka’s models are trained from scratch and extensively optimized for production RAG use cases that include unstructured multimodal data. It includes the following features:
Long context: Trained to reason over entire business documents with both structured and unstructured data in the context, Reka’s suite of models support 128k context length by default plus an additional long-context variant that can process up to 400k context length (equivalent to ~1000 pages of documents).
Mixed data types: Enhanced performance for prompts that include both structured (i.e., table) and unstructured data (i.e.,text, video, image, audio) in their context.
Optimized for retrieval: Optimized to handle retrieved context in a RAG setting. For example, Reka’s models are trained with the capability to assess relevancy of a set of semantically similar chunks in a retrieved context.
These models will be available on Q3 2024. Join the waitlist today. Get priority access to our models.
Author
