Reka Responsible AI, Model Risk, Ethics & Governance Framework
Today, we are open sourcing a research preview of a new version of Reka Flash 3, our 21 billion parameters model. Reka Flash 3 is a compact, general-purpose model that excels at general chat, coding, instruction following, and function calling. The current version performs competitively with proprietary models such as OpenAI o1-mini, making it a good model to build many applications that require low latency or on-device deployments. It is currently the best model in its size category .
Training process. This model was pretrained from scratch on a diverse set of publicly accessible and synthetic datasets. We instruction-tuned the base model on curated, high-quality data to optimize its performance. In the final stage, we performed reinforcement learning with REINFORCE Leave One-Out (RLOO) using both model-based and rule-based rewards to improve the capabilities. We focus on general improvements in our reinforcement learning stage, as opposed to a specialized model for mathematics or coding. The version that we release has 32k context length. We share it with the community as an early research preview, as our internal version continues to improve with more training steps. This model can serve as a great foundation for building domain-specific models or your own reasoning engine.
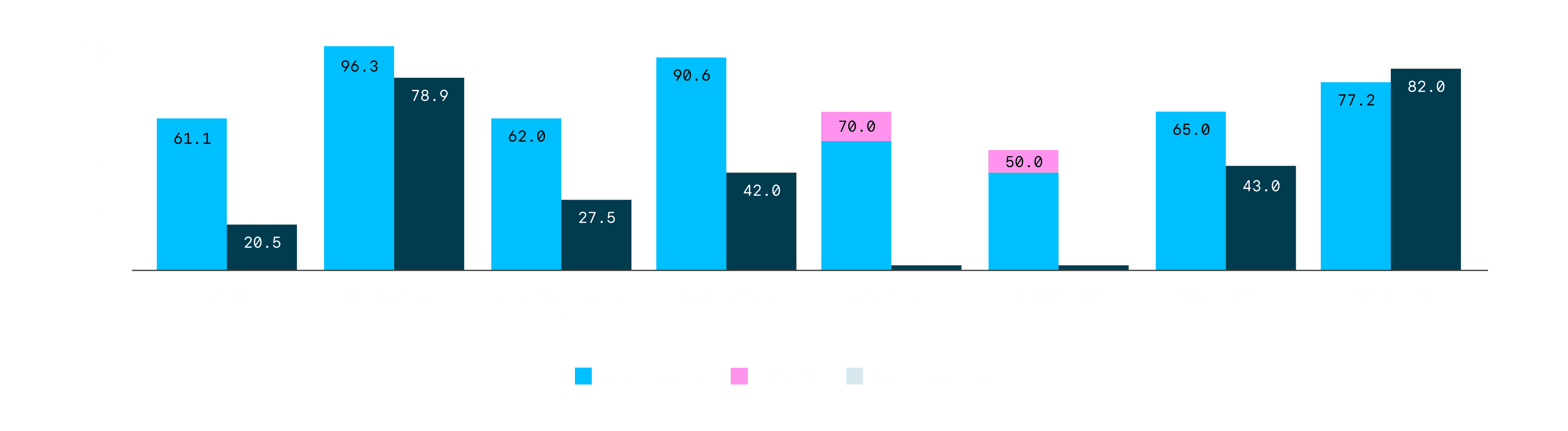
Performance of Reka Flash 3 compared to o1-mini and QwQ-32B. We note that while QWQ-32B performs much better on AIME’24, it is comparable to Reka Flash 3 on AIME’25. In addition, there might be contaminations of LiveCodeBench-v5 data (5/1/2023-2/1/2025) for QwQ-32B, since a score of 86.0 makes it better than any other existing models (https://livecodebench.github.io/leaderboard.html).
Reka Flash 3 is a significant improvement over the previous version of Reka Flash 2.5
On-device deployment. Reka Flash 3 is a great choice for cost-efficient applications that require low-latency or local deployments. As a 21B parameters model, Reka Flash 3 has 35% fewer parameters than QwQ-32B. The full precision of Reka Flash 3 comes at 39GB (fp16). You can compress it to as small as 11GB while maintaining performance with 4-bit quantization. In comparison, QwQ-32B requires 64GB at bf16 and 18GB with 4-bit quantization.
Budget forcing. Reka Flash 3 thinks before it produces an output. We use <reasoning> </reasoning> tags to indicate the beginning and the end of its thinking process. For some problems, the model might think for a long time. You can make the model to stop its thinking process by forcing it to output </reasoning> after a certain number of steps. We observe such a budget forcing mechanism will still produce a reasonable output. We show performance on AIME-2024 (cons@16) for various budgets below.
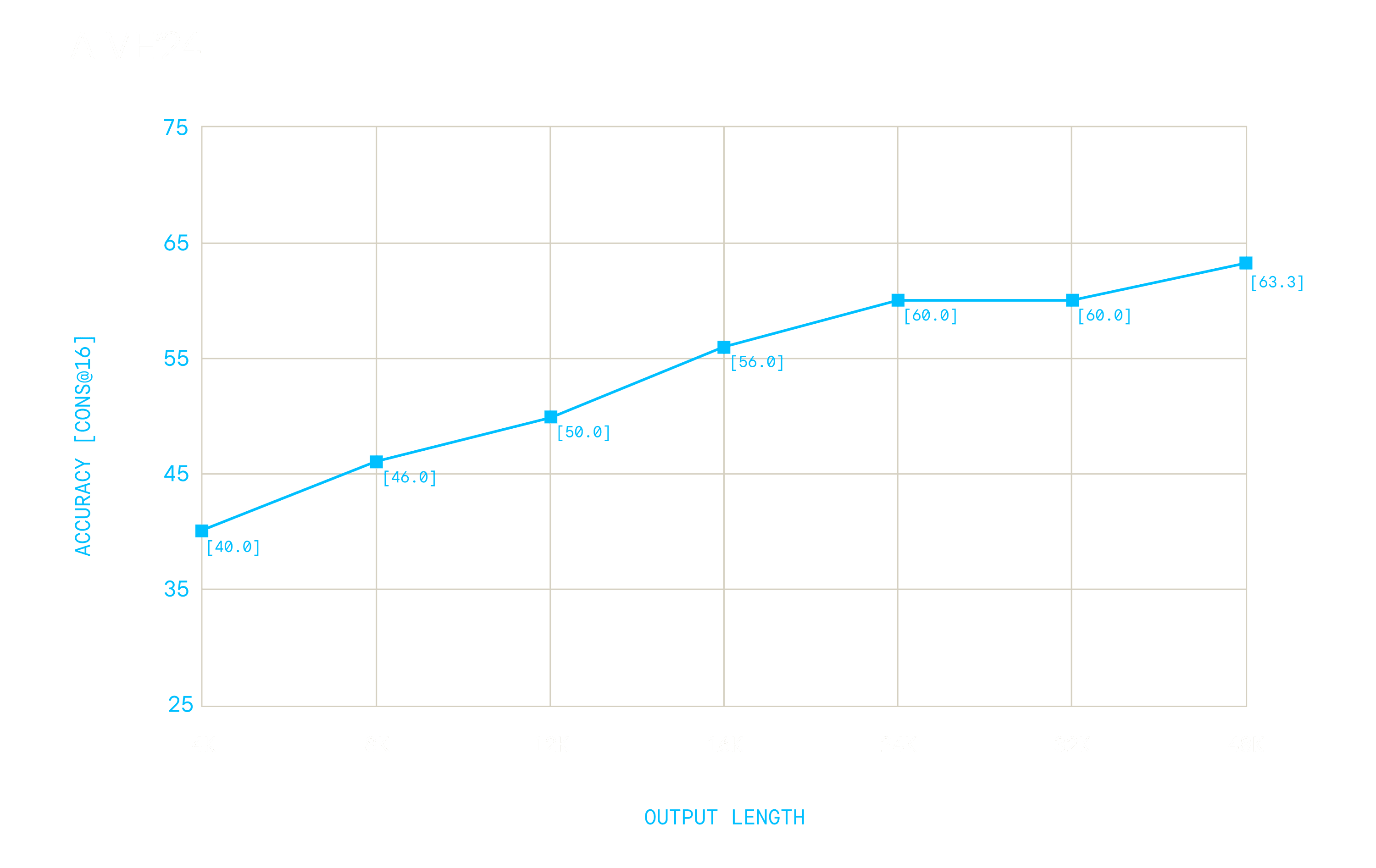
While performance of Reka Flash 3 continues to improve with more reasoning time, it is possible to control it to a pre-specified budget.
Language support. This version is primarily built for the English language, so you should consider this an English only model. However, the model is able to understand other languages to some degree, as can be seen by its performance on BeleBele below. On WMT’23, this model achieves 83.2 COMET score (all languages).
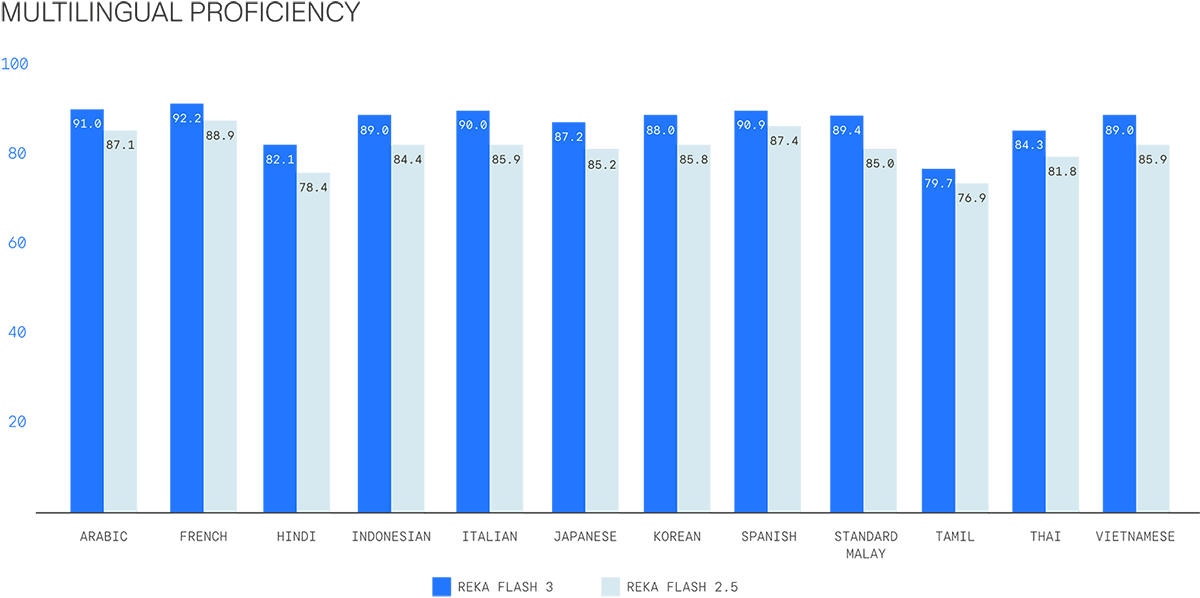
Improvements from the previous version of Reka Flash on multilingual understanding as measured by scores on Belebele.
Release notes:
As a smaller model, it is not the best model for knowledge-intensive tasks, as can be seen from its MMLU-Pro score that is only 65.0 (although this is still better than many larger models out there). We recommend coupling Reka Flash 3 with web search for knowledge-related tasks.
The model often thinks in English when prompted questions in non-English languages. We observe that this sometimes affects the output quality in non-English languages.
The model has not undergone extensive alignment or persona training.
Reka Flash 3 is available to try on Reka Space. We use an improved version that is trained to work with our first-party tools for Reka Nexus.
The model weights are available to download and modify under Apache 2.0 license. It is a great model for developers and researchers who need a powerful but lightweight model to build on. Enterprises that require longer context, customization, multimodality, or secure on-premise or on-device deployments with increased speed and lower memory requirements using our quantization method can contact us.
Author
